
Our GCC compiler for the EnCore platform is based on the ARC GNU
toolchain (GCC version 4.2.1) with its support for the ARC 600 and
ARC 700 processors. Due to the full instruction set compatibility
with these commercial processors a plain, non-modified ARC-GCC
distribution can be used for code generation for EnCore.
Building on top of an established instruction set architecture and
an existing open-source software toolchain has several advantages for
a research project such as PASTA. First, a working set of software
development tools is available right from the start of the project.
Second, the effort for infrastructure development is minimised. Third,
any new compiler optimisations developed by the GCC community are
directly available and further improve our compiler at no cost.
Among the features of the plain ARC-GCC toolchain are:
- Floating-point support. The compiler can be directed to emit genuine floating-point instructions or to use software emulation for floating-point operations.
- Mixed mode code generation. ARCompact 16bit instructions are intermixed with 32bit instructions. This results in higher code density (=lower code size) and better instruction cache behaviour.
- Zero-overhead loops. Hardware loops support efficient 'for' loop implementation and are generated wherever possible.
EnCore specific extensions
In the PASTA project we have extended the original ARC-GCC compiler with
code generation passes that deal with the EnCore-specific custom
instructions resulting from automated instruction set extension.
Current ISE methodologies are typically limited to single applications, i.e.
there is no compiler support available for complex instructions patterns
generated by previous ISE identification and synthesis stages. Instead, the ISE
identification tool specifies where the instructions should be used.
To be able to attempt to re-use instructions in additional programs to the ones
they were generated for we implemented a complex instruction selector within
GCC. Unusually, this performs instruction selection at the GIMPLE level. The
reason for this is that it identifies matches based on the same internal
representation as the ISE identification tool and this representation is
constructed from GIMPLE, it also avoids the well-known difficulties in
extending the expand GENERIC-to-RTL pass with machine-specific higher
level instructions. Only complex instructions are matched by this pass, so
many GIMPLE nodes will not be covered, these are handled by standard
instruction selection in the back-end. The standard back-end is not used with
the complex instructions as its pattern matching capabilities are not able to
handle the large graphs that describe the instructions being considered here.
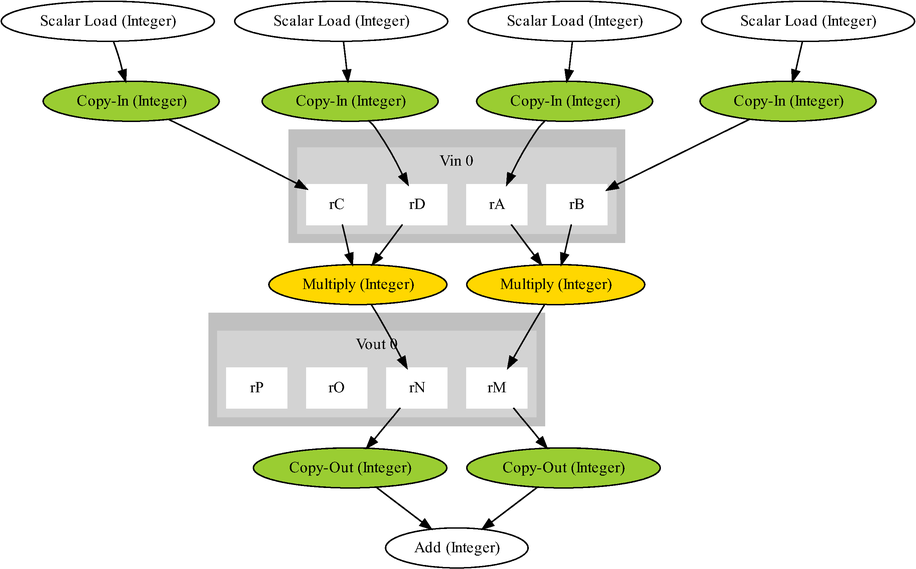
A trivial hand-written example of an instruction matched to a basic block is
shown in the diagram below. The graph shows a basic block that
contains two non-dependent integer multiplies and an addition, the multiplies
are implemented by an extension instruction. The copy nodes
should be able to be eliminated during register allocation, so won't actually
result in any move instructions being used.
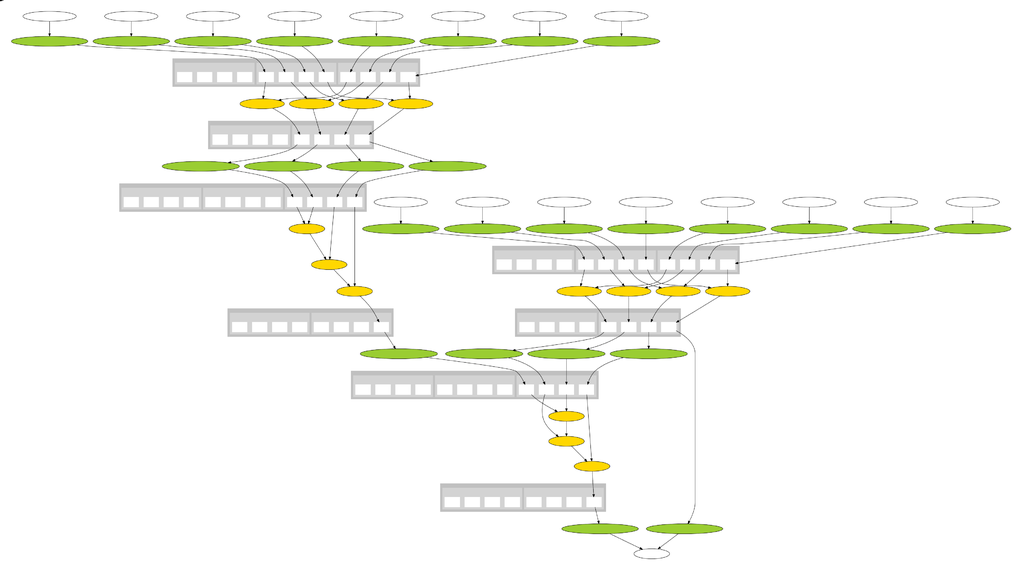
The next figure shows a more realistic example where four instructions are
matched to a larger basic block.
Links to the MilePost project
The PASTA project maintains close links to the EU-funded MilePost project where machine learning for embedded program optimisation is investigated. In particular, MilePost has extended the ARC port of the GCC compiler (the same that we are using in the PASTA project) with the ability to automatically tune its optimisation engine to new hardware configurations (e.g. cache sizes) and applications. As a result the MilePost GCC compiler regularly outperforms the manually tuned baseline GCC compiler and our own EnCore compiler can take immediate advantage of this on-going optimisation effort.
Publications
- O.Almer, R.V.Bennett, I.Böhm, A.C.Murray, X.Qu, M.Zuluaga, B.Franke and N.P.Topham.
An End-to-End Design Flow for Automated Instruction Set Extension and Complex Instruction Selection based on GCC
Proceedings of the 1st International Workshop on GCC Research Opportunities (GROW'09), Paphos, Cyprus, 2009.
