
Sharing HW resources between Instructions
Generally, customisation increases processor performance as additional special instructions are added. Nevertheless, performance is not the only metric that modern systems must take into account; die area and energy efficiency are equally important.
There has been plenty of research focused on developing techniques that allow a compiler to automatically identify Instruction Set Extension (ISE) candidates. However, efficient synthesis of these instructions is a problem that has not had much attention.
Resource sharing during synthesis of ISEs can reduce significantly the die area of a customised processor. This may increase the number of custom instructions that can be synthesised with a given area budget. Resource sharing involves combining the graph representations of two or more ISEs which contain a similar sub-graph. This coupling of multiple sub-graphs, if performed naively, can increase the latency of the extension instructions considerably. The question now would be how to merge a collection of ISEs to reduce area while minimising the increase in latency,
Based on existing resource-sharing techniques, we developed a new heuristic that controls the degree of resource sharing between a given set of custom instructions, given that design objectives are not always extremes as minimum execution time, or minimum die area. There are many possible intermediate points in the area-delay relationship, any one of which may be ideal for a given system.
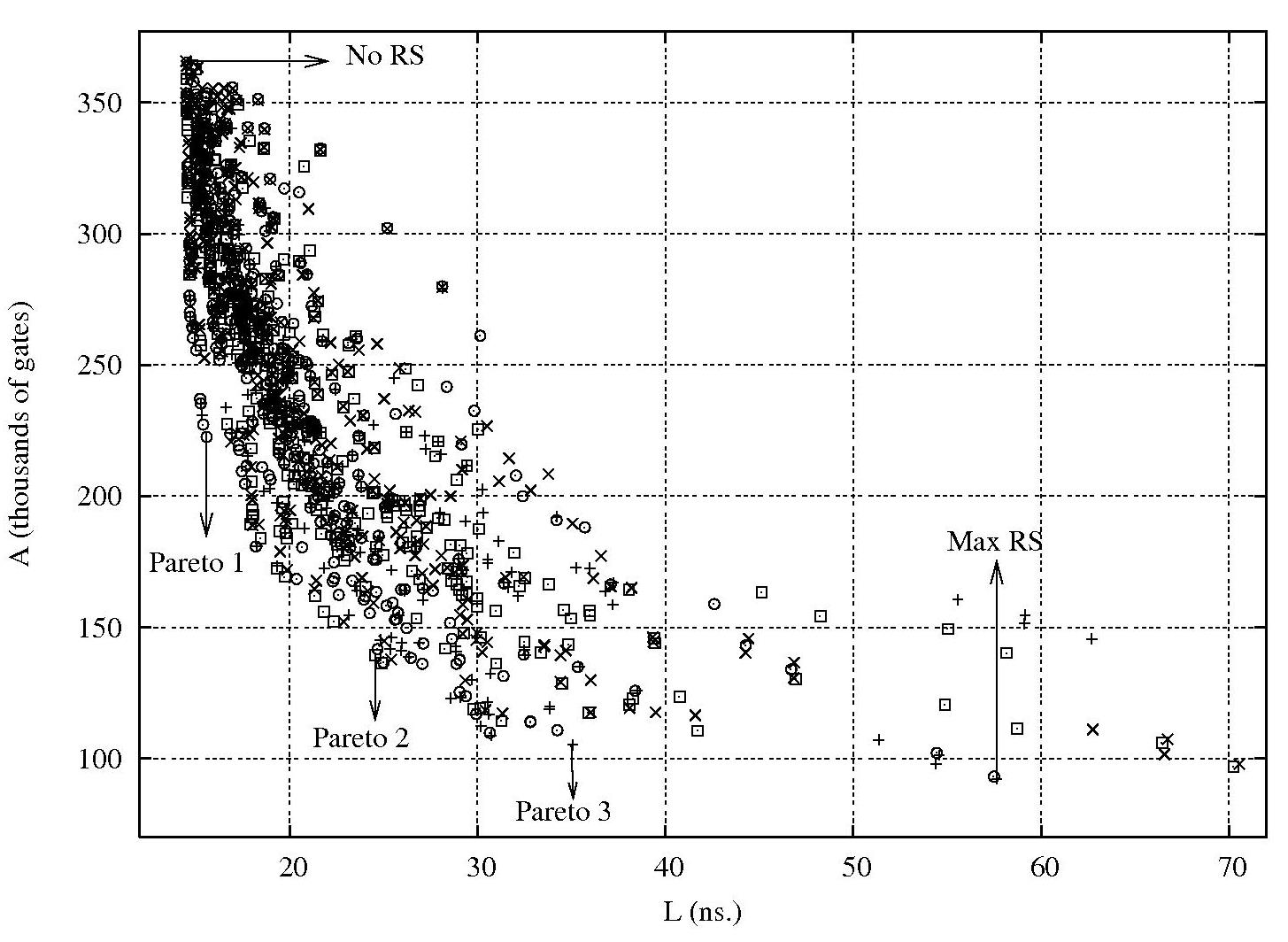
This work addresses ISE implementation issues by focussing on the problem of how to explore the design space of customised processors which may support a wider collection of extensions. It has been shown that an appropriate level of resource sharing provides a significantly simpler design with only modest increases in average latency for extension instructions. Our heuristic is able to explore the space to find solutions that achieve the right compromise between latency and area. Results show that die area is excessive when resource sharing is disabled, whereas very aggressive resource sharing leads to high latency.
Each instruction is represented as a data flow graph represented by a set of vertices V and a set of edges E, where vertices are operators, inputs or outputs, and edges indicate the data dependencies between them. Resource sharing is induced by the search for maximum common substrings between two paths. A maximum common substring is a subsequence of vertices that maximizes area reduction. The area of a substring is given by the sum of the areas of each operation within the substring.
The resource-sharing heuristic was implemented as a system that takes input graphs expressed in XML. The algorithm is parameterised by three threshold values. Each of these is given a real value between 0 and 1. The value given to these parameters is varied in order to find the different possible implementation alternatives that represent different tradeoffs in the design space. After performing resource sharing the system outputs a description of the resulting merged logic in Verilog to enable subsequent logic synthesis and integration with an existing processor core.
As shown in the figure below, different tradeoffs between area and average latency of a set of ISEs can be unveiled by varying the parameters. The solution given by the No RS point has no resource sharing applied, and therefore has the smallest latency but the largest area. In contrast, for Max RS, the algorithm merges all ISEs without any restrictions, as in non-parameterized approaches. Pareto 1, Pareto 2 and Pareto 3, represent possible implementation alternatives with varying tradeoffs between latency and area.
Publications
- M. Zuluaga and N.P. Topham
Resource Sharing in Custom Instruction Set Extensions
Proceedings of the 6th IEEE Symposium on Application Specific Processors, Anaheim, CA, June 2008.
