AMI Corpus Overview
A brief introduction to the AMI Meeting Corpus.
This is a web version of the following newsletter article:
Carletta, J. (2006) Announcing the AMI Meeting Corpus. The ELRA Newsletter 11(1), January-March, p. 3-5.
Announcing the AMI Meeting Corpus
The European-funded AMI project (FP6-506811) is a 15-member multi-disciplinary consortium dedicated to the research and development of technology that will help groups interact better. One AMI focus is on developing meeting browsers that improve work group effectiveness by giving better access to the group's history. Increasingly in future, we will be considering how related technologies can help group members joining a meeting late or having to "attend" from a different location. In both cases, a key part our approach is to index meetings for the properties that users find salient. This might mean, for instance, spotting topic boundaries, decisions, intense discussions, or places where a specific person or subject was mentioned. To help with developing this indexing the consortium has collected the AMI Meeting Corpus, a set of recorded meetings that is now available as a public resource. Although the data set was designed specifically for the project, it could be used for many different purposes in linguistics, organizational and social psychology, speech and language engineering, video processing, and multi-modal systems.
The AMI Meeting Corpus consists of 100 hours of meeting recordings. The recordings use a range of signals synchronized to a common timeline. These include close-talking and far-field microphones, individual and room-view video cameras, and output from a slide projector and an electronic whiteboard. During the meetings, the participants also have unsynchronized pens available to them that record what is written. The meetings were recorded in English using three different rooms with different acoustic properties, and include mostly non-native speakers.

Figure 1: AMI's three instrumented meeting rooms.
The most useful speech corpora are those that come with annotations. The AMI Meeting Corpus includes high quality, manually produced orthographic transcription for each individual speaker, including word-level timings that have derived by using a speech recognizer in forced alignment mode. It also contains a wide range of other annotations, not just for linguistic phenomena but also detailing behaviours in other modalities. These include dialogue acts; topic segmentation; extractive and abstractive summaries; named entities; the types of head gesture, hand gesture, and gaze direction that are most related to communicative intention; movement around the room; emotional state; and where heads are located on the video frames. The linguistically motivated annotations have been applied the most widely, and cover all of the scenario-based recordings. Other annotations are more limited, but in each case we have chosen what we consider a sensible data subset. For phenomena that are sparse in the meeting recordings, we have marked up auxiliary recordings where the behaviours are more common. These are also included in the corpus.
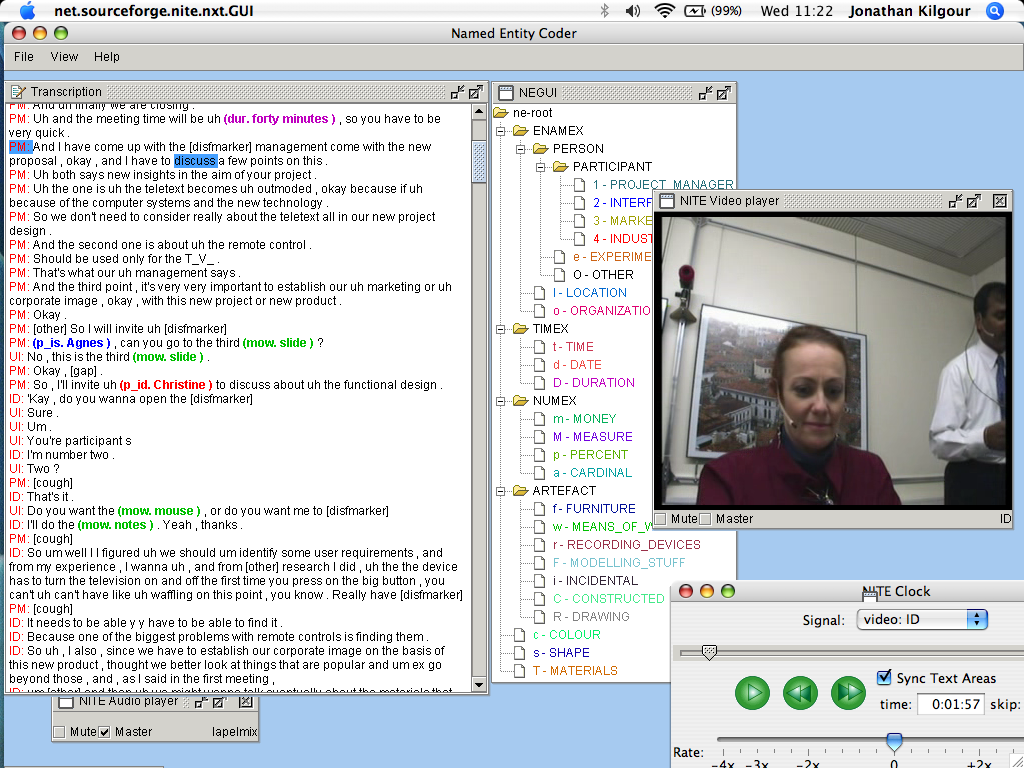
Figure 2: The NXT-based coding tool used to create named entity annotation for the AMI Meeting Corpus.
There are a number of features that make the AMI Meeting Corpus a bit different from previous corpora. The first is its release under a Creative Commons Attribution Licence. This form of licensing is intended to create an environment in which people freely share what they have created. The corpus license allows users to copy, distribute, and display the data for any purpose as long as the AMI project is credited.
Another feature of note is that unlike for most previous corpora, all of the annotations provided are in one consistent format that represents not just the timecourse of the annotations, but also how they relate structurally to the transcription and to other annotations. For instance, topic segments and dialogue acts are represented not just as labelled spans with a start and end time, but as timed sequences of words. Extractive summaries do not just pull out segments of the meetings by time, but point to the dialogue act (and from there, the words) to be extracted, as well as any sentences in the meeting abstract that relate to the extracted segment. This kind of representation, which can be built and searched using the open source NITE XML Toolkit, allows for much richer investigation of the data than is possible using simple timestamping. It also makes data sharing a more attractive proposition, since it makes integrating new annotations easier and increases their possible uses. In the past, annotations have been created by many different sites for popular data sets like the Switchboard Corpus, but sharing has been patchy. Our license terms and data representation are both designed to move the community to a model in which we pool our resources better.
Finally, the AMI Meeting Corpus has a somewhat unusual design. Except for corpora set up to inform a spoken dialogue systems application by showing what the system needs to produce, dialogue corpus designers usually aim to capture completely natural, uncontrolled conversations. Around one-third of our data is like this; it consists of meetings from various groups that would have happened whether they were being recorded or not. However, the rest has been collected by having the participants play different roles in a fictitious design team that takes a new project from kick-off to completion over the course of a day. The day starts with training for the participants about what is involved in the roles they have been assigned (industrial designer, interface designer, marketing, or project manager) and then contains four meetings, plus individual work to prepare for them and to report on what happened. All of their work is embedded in a very mundane work environment that includes web pages, email, text processing, and slide presentations.
This sort of role-playing has some striking advantages over natural data, particularly for research that relies on the meaning of what was said. First and foremost, measures for the quality of a group outcome can be built in. Valid measures are very difficult to obtain for natural groups, but they are invaluable for assessing whether technologies for assisting human groups actually help. Although none of the groups in the AMI Meeting Corpus use browsers to access their past meetings, we intend to collect groups that do in the near future so that we can compare their outcomes both to unassisted groups and to each other. In addition, the behaviour of role-playing groups is easier to understand than that of natural groups. This is because the researcher is in control of the participants' knowledge and motivation, and because the groups don't come with years of personal history that cause them to behave differently than they would otherwise. The usual disadvantage expressed for role-playing is that there is no guarantee participants will care enough about what they do to provide data comparable to natural interaction. In our experience, as long as the role-play is set up carefully, participants in role-playing fully engage in what they are doing. However, the reason why the corpus is not completely made up of controlled data is as a safeguard, both against any possible disadvantages of role-playing and against the domain limitations it entails. The inclusion of both controlled and natural data allows researchers to develop new techniques on the controlled data first and then begin to test their generalizability using the natural material.
Our main way of releasing the corpus is through the website http://corpus.amiproject.org. At the website, anyone can look at the signals for one meeting and read extensive documentation. After registration, users can browse meetings online using SMIL presentations, download their chosen data, and participate in a discussion forum. Registration is simple and free. Everything that has been released is on the website, apart from the full-size videos. These are too large for download, but the website gives a contact for ordering firewire drives that contain them, priced at the cost of production. In addition to the website, we have also produced 500 copies of a "taster" DVD that includes everything for a single meeting - signals, transcripts, and every available annotation, including samples of some types that have not yet formed part of the public release. The DVD can currently be ordered for free from the website.
The AMI Meeting Corpus has required substantial investment. We expect it to become an invaluable resource to the broader research community, as it provides novel data for research and evaluation in many different areas. The AMI project consortium will continue working together in the newly-funded AMIDA project, and therefore intends both to maintain the corpus and to take an interest in its growth. We are happy to have it used, and hope that it will attract researchers with other approaches to our own problems, but also be taken in new and unforeseen directions.
AMI Project, http://www.amiproject.org; AMI Meeting Corpus, https://www.idiap.ch/dataset/ami/; NITE XML Toolkit, http://www.ltg.ed.ac.uk/NITE.