Universal Representation Learning from Multiple Domains for Few-shot Classification
ICCV 2021
Abstract
Universal Representation Learning
Our method (illustrated in Figure 1) learns a single universal feature extractor \(f_{\phi}\) that is distilled from multiple feature extractors \(\{f_{\phi^{\ast}_\tau}\}_{\tau}^{K}\) during meta-training.
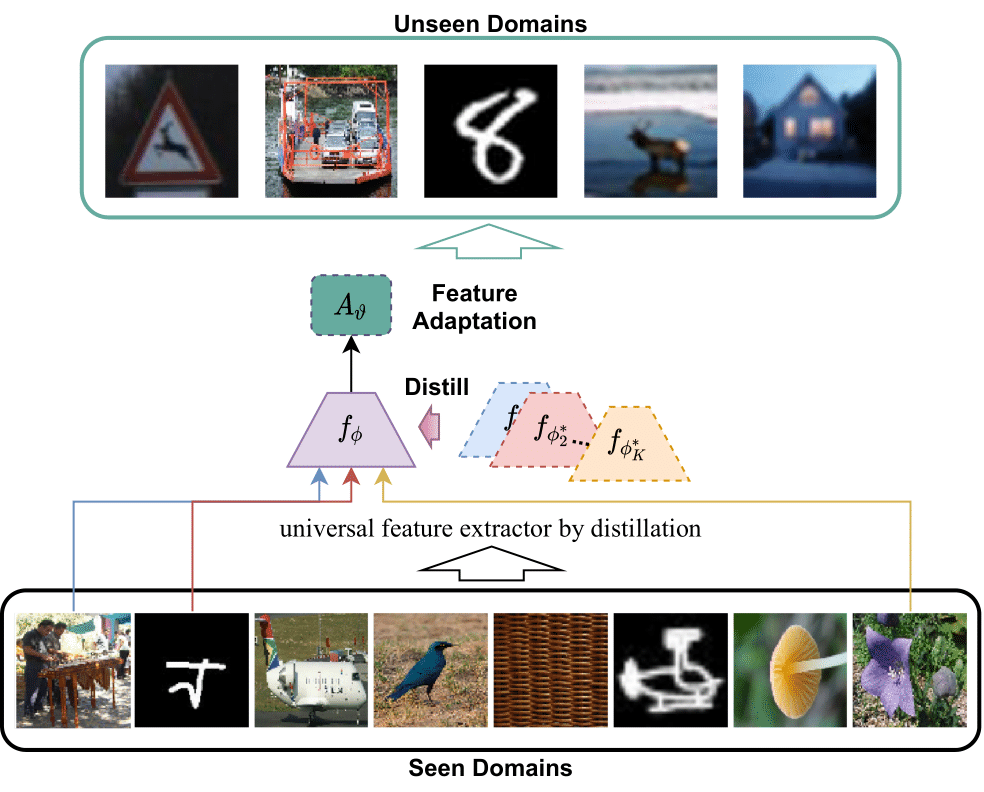
Feature adaptation in meta-test
In meta-test stage, we use a linear transformation \(A_{\vartheta}\) to further refine the universal representations to unseen domains as illustrated in Figure 2.
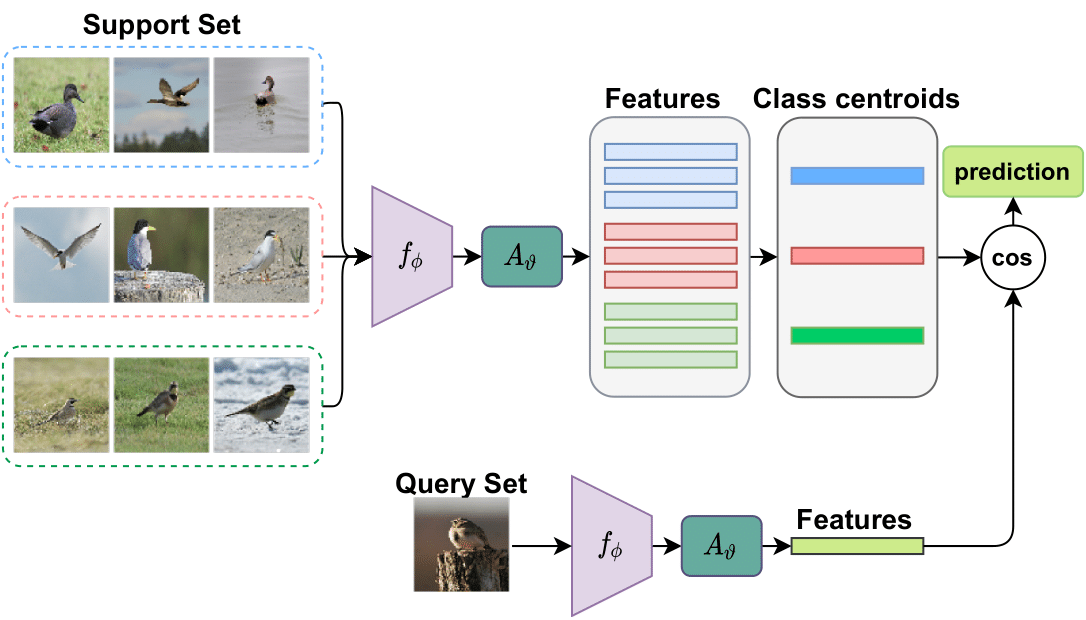
Results
| Test Datasets | URL (Ours) | MDL | Best SDL | URT [6] | SUR [4] | Simple CNAPS [5] | CNAPS [2] | BOHB-E [3] | Proto-MAML [1] |
|---|---|---|---|---|---|---|---|---|---|
| Avg rank | 1.2 | 4.8 | 4.8 | 4.2 | 5.4 | 4.8 | 6.8 | 8.0 | 7.7 |
| ImageNet | 57.5±1.1 | 52.9±1.2 | 54.3±1.1 | 55.0±1.1 | 54.5±1.1 | 56.5±1.1 | 50.8±1.1 | 51.9±1.1 | 46.5±1.1 |
| Omniglot | 94.5±0.4 | 93.7±0.5 | 93.8±0.5 | 93.3±0.5 | 93.0±0.5 | 91.9±0.6 | 91.7±0.5 | 67.6±1.2 | 82.7±1.0 |
| Aircraft | 88.6±0.5 | 84.9±0.5 | 84.5±0.5 | 84.5±0.6 | 84.3±0.5 | 83.8±0.6 | 83.7±0.6 | 54.1±0.9 | 75.2±0.8 |
| Birds | 80.5±0.7 | 79.2±0.8 | 70.6±0.9 | 75.8±0.8 | 70.4±1.1 | 76.1±0.9 | 73.6±0.9 | 70.7±0.9 | 69.9±1.0 |
| Textures | 76.2±0.7 | 70.9±0.8 | 72.1±0.7 | 70.6±0.7 | 70.5±0.7 | 70.0±0.8 | 59.5±0.7 | 68.3±0.8 | 68.2±0.8 |
| Quick Draw | 81.9±0.6 | 81.7±0.6 | 82.6±0.6 | 82.1±0.6 | 81.6±0.6 | 78.3±0.7 | 74.7±0.8 | 50.3±1.0 | 66.8±0.9 |
| Fungi | 68.8±0.9 | 63.2±1.1 | 65.9±1.0 | 63.7±1.0 | 65.0±1.0 | 49.1±1.2 | 50.2±1.1 | 41.4±1.1 | 42.0±1.2 |
| VGG Flower | 92.1±0.5 | 88.7±0.6 | 86.7±0.6 | 88.3±0.6 | 82.2±0.8 | 91.3±0.6 | 88.9±0.5 | 87.3±0.6 | 88.7±0.7 |
| Traffic Sign | 63.3±1.2 | 49.2±1.0 | 47.1±1.1 | 50.1±1.1 | 49.8±1.1 | 59.2±1.0 | 56.5±1.1 | 51.8±1.0 | 52.4±1.1 |
| MSCOCO | 54.0±1.0 | 47.3±1.1 | 49.7±1.0 | 48.9±1.1 | 49.4±1.1 | 42.4±1.1 | 39.4±1.0 | 48.0±1.0 | 41.7±1.1 |
| MNIST | 94.5±0.5 | 94.2±0.4 | 91.0±0.5 | 90.5±0.4 | 94.9±0.4 | 94.3±0.4 | - | - | - |
| CIFAR-10 | 71.9±0.7 | 63.2±0.8 | 65.4±0.8 | 65.1±0.8 | 64.2±0.9 | 72.0±0.8 | - | - | - |
| CIFAR-100 | 62.6±1.0 | 54.7±1.1 | 56.2±1.0 | 57.2±1.0 | 57.1±1.1 | 60.9±1.1 | - | - | - |
[1] Eleni Triantafillou, Tyler Zhu, Vincent Dumoulin, Pascal Lamblin, Utku Evci, Kelvin Xu, Ross Goroshin, Carles Gelada, Kevin Swersky, Pierre-Antoine Manzagol, Hugo Larochelle; Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples; ICLR 2020.
[2] James Requeima, Jonathan Gordon, John Bronskill, Sebastian Nowozin, Richard E. Turner; Fast and Flexible Multi-Task Classification Using Conditional Neural Adaptive Processes; NeurIPS 2019.
[3] Tonmoy Saikia, Thomas Brox, Cordelia Schmid; Optimized Generic Feature Learning for Few-shot Classification across Domains; arXiv 2020.
[4] Nikita Dvornik, Cordelia Schmid, Julien Mairal; Selecting Relevant Features from a Multi-domain Representation for Few-shot Classification; ECCV 2020.
[5] Peyman Bateni, Raghav Goyal, Vaden Masrani, Frank Wood, Leonid Sigal; Improved Few-Shot Visual Classification; CVPR 2020.
[6] Lu Liu, William Hamilton, Guodong Long, Jing Jiang, Hugo Larochelle; Universal Representation Transformer Layer for Few-Shot Image Classification; ICLR 2021.
Qualitative Results
We also qualitatively analyze our method and compare it to URT [6] in Figure 3 by illustrating the nearest neighbors in four different datasets given a query image (see supplementary for more examples). While URT retrieves images with more similar colors, shapes and backgrounds, our method is able to retrieve semantically similar images and finds more correct neighbors than URT. It again suggests that our method is able to learn more semantically meaningful and general representations.
