Publications
2026
-

Zadrozny, J., Mac Aodha, O., & Bilen, H. (2026). BAT3R: Bootstrapping Articulated 3D Reconstruction from 2D Image Collections. European Conference on Computer Vision (ECCV).
3D reconstruction of articulated objects from a single image is challenging because large training datasets with paired image and 3D supervision are difficult to obtain. Recent point map-based methods achieve strong performance but rely on synthetic datasets rendered from manually created articulated 3D assets with carefully curated pose distributions. While camera viewpoints can be easily sampled, generating realistic object articulations remains costly and labor-intensive. We propose a training framework that reduces this requirement by leveraging unannotated 2D images collections with only a single rigged canonical mesh per category. Starting from a weak 3D shape predictor trained on canonical-pose renders, we iteratively estimate object articulation and camera pose by fitting the mesh to predicted point maps. The recovered articulations and viewpoints are then used to render updated synthetic training data, progressively improving the predictor. Despite using substantially weaker 3D supervision, our models achieve performance comparable with DualPM,which requires manually curated articulated training datasets.@inproceedings{Zadrozny26, title = {BAT3R: Bootstrapping Articulated 3D Reconstruction from 2D Image Collections}, author = {Zadrozny, Jakub and Mac~Aodha, Oisin and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2026}, xpdf = {https://arxiv.org/pdf/2607.03891}, xcode = {https://jakubzadrozny.github.io/bat3r/} } -

Ye, Z., Danier, D., Zhao, B., & Bilen, H. (2026). Training-free Discriminative Patch Mining for Robust Few-Shot Recognition with CLIP. European Conference on Computer Vision (ECCV).
Few-shot classification performance of Contrastive Language-Image Pre-training (CLIP) varies widely across datasets, especially when class names provide weak or ambiguous semantic priors.This issue is alleviated in vision-only fine-grained methods, as they identify discriminative local features but require training on the full dataset.We thus introduce a training-free approach that integrates discriminative patches into CLIP to reduce reliance on textual prompts. Our method identifies patches with high intra-class consistency and low inter-class ambiguity, forming a Class-Discriminative Patch Set (CDPS) for each category. Using CDPS, we enhance the recognition ability of CLIP through a hybrid classifier combining global image-text alignment with local patch-based similarity.@inproceedings{Ye26, title = {Training-free Discriminative Patch Mining for Robust Few-Shot Recognition with CLIP}, author = {Ye, Zhenzhang and Danier, Duolikun and Zhao, Bo and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2026}, xcode = {https://github.com/VICO-UoE/CDPS} } -
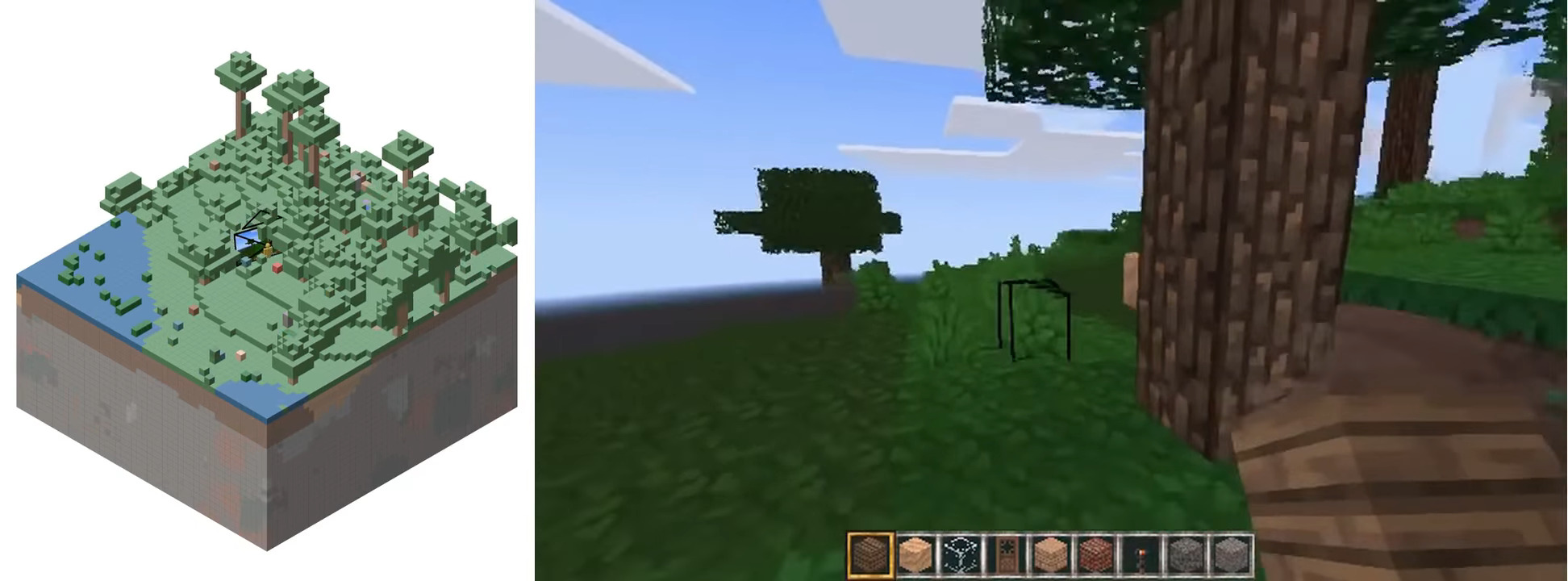
Garcin, S., Walker, T., McDonagh, S., Pearce, T., Bilen, H., He, T., Wang, K., & Bian, J. (2026). Beyond Pixel Histories: World Models with Persistent 3D State. International Conference on Machine Learning (ICML).
Interactive world models continually generate video by responding to a user’s actions, enabling open-ended generation capabilities. However, existing models typically lack a 3D representation of the environment, meaning 3D consistency must be implicitly learned from data, and spatial memory is restricted to limited temporal context windows. This results in an unrealistic user experience and presents significant obstacles to downstream tasks such as training agents. To address this, we present PERSIST, a new paradigm of world model which simulates the evolution of a latent 3D scene: environment, camera, and renderer. This allows us to synthesise new frames with persistent spatial memory and consistent geometry. Both quantitative metrics and a qualitative user study show substantial improvements in spatial memory, 3D consistency, and long-horizon stability over existing methods, enabling coherent, evolving 3D worlds. We further demonstrate novel capabilities, including synthesising diverse 3D environments from a single image, as well as enabling fine-grained, geometry-aware control over generated experiences by supporting environment editing and specification directly in 3D space. Project page@inproceedings{Garcin26, title = {Beyond Pixel Histories: World Models with Persistent 3D State}, author = {Garcin, Samuel and Walker, Thomas and McDonagh, Steven and Pearce, Tim and Bilen, Hakan and He, Tianyu and Wang, Kaixin and Bian, Jiang}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2026}, xpdf = {https://arxiv.org/pdf/2603.03482}, xcode = {https://francelico.github.io/persist.github.io/} } -

Du, Z., Danier, D., Lenssen, J. E., & Bilen, H. (2026). MoonSeg3R: Monocular Online Zero-Shot Segment Anything in 3D with Reconstructive Foundation Priors. IEEE/CVF Conference on Computer Vision and Pattern Recognition Findings (CVPRF).
In this paper, we focus on online zero-shot monocular 3D instance segmentation, a novel practical setting where existing approaches fail to perform because they rely on posed RGB-D sequences. To overcome this limitation, we leverage CUT3R, a recent Reconstructive Foundation Model (RFM), to provide reliable geometric priors from a single RGB stream. We propose MoonSeg3R, which introduces three key components:(1) a self-supervised query refinement module with spatial-semantic distillation that transforms segmentation masks from 2D visual foundation models (VFMs) into discriminative 3D queries;(2) a 3D query index memory that provides temporal consistency by retrieving contextual queries; and (3) a state-distribution token from CUT3R that acts as a mask identity descriptor to strengthen cross-frame fusion. Experiments on ScanNet200 and SceneNN show that MoonSeg3R is the first method to enable online monocular 3D segmentation and achieves performance competitive with state-of-the-art RGB-D-based systems. Our code is available at https://github.com/VICO-UoE/MoonSeg3R.@inproceedings{Du26, title = {MoonSeg3R: Monocular Online Zero-Shot Segment Anything in 3D with Reconstructive Foundation Priors}, author = {Du, Zhipeng and Danier, Duolikun and Lenssen, Jan~Eric and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Findings (CVPRF)}, year = {2026}, xpdf = {https://openaccess.thecvf.com/content/CVPR2026F/papers/Du_MoonSeg3R_Monocular_Online_Zero-Shot_Segment_Anything_in_3D_with_Reconstructive_CVPRF_2026_paper.pdf}, xcode = {https://github.com/VICO-UoE/MoonSeg3R} }
2025
-

Cheng, Y., Goel, A., & Bilen, H. (2025). Visually interpretable subtask reasoning for visual question answering. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).
Answering complex visual questions like ’Which red furniture can be used for sitting?’ requires multi-step reasoning, including object recognition, attribute filtering, and relational understanding. Recent work improves interpretability in multimodal large language models (MLLMs) by decomposing tasks into sub-task programs, but these methods are computationally expensive and less accurate due to poor adaptation to target data. To address this, we introduce VISTAR (Visually Interpretable Subtask-Aware Reasoning Model), a subtask-driven training framework that enhances both interpretability and reasoning by generating textual and visual explanations within MLLMs. Instead of relying on external models, VISTAR fine-tunes MLLMs to produce structured Subtask-of-Thought rationales (step-by-step reasoning sequences). Experiments on two benchmarks show that VISTAR consistently improves reasoning accuracy while maintaining interpretability.@inproceedings{Cheng25, title = {Visually interpretable subtask reasoning for visual question answering}, author = {Cheng, Yu and Goel, Arushi and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, year = {2025}, xpdf = {https://www.openaccess.thecvf.com/content/CVPR2025W/XAI4CV/papers/Cheng_Visually_Interpretable_Subtask_Reasoning_for_Visual_Question_Answering_CVPRW_2025_paper.pdf}, xcode = {https://github.com/ChengJade/VISTAR} } -

Mariotti, O., Du, Z., Bhalgat, Y., Mac Aodha, O., & Bilen, H. (2025). Jamais Vu: Exposing the Generalization Gap in Supervised Semantic Correspondence. Neural Information Processing Systems (NeurIPS).
Semantic correspondence (SC) aims to establish semantically meaningful matches across different instances of an object category. We illustrate how recent supervised SC methods remain limited in their ability to generalize beyond sparsely annotated training keypoints, effectively acting as keypoint detectors. To address this, we propose a novel approach for learning dense correspondences by lifting 2D keypoints into a canonical 3D space using monocular depth estimation. Our method constructs a continuous canonical manifold that captures object geometry without requiring explicit 3D supervision or camera annotations. Additionally, we introduce SPair-U, an extension of SPair-71k with novel keypoint annotations, to better assess generalization. Experiments not only demonstrate that our model significantly outperforms supervised baselines on unseen keypoints, highlighting its effectiveness in learning robust correspondences, but that unsupervised baselines outperform supervised counterparts when generalized across different datasets.@inproceedings{Mariotti25, title = {Jamais Vu: Exposing the Generalization Gap in Supervised Semantic Correspondence}, author = {Mariotti, Octave and Du, Zhipeng and Bhalgat, Yash and Mac~Aodha, Oisin and Bilen, Hakan}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2025}, xpdf = {https://arxiv.org/pdf/2506.08220}, xcode = {https://github.com/VICO-UoE/JamaisVu} } -
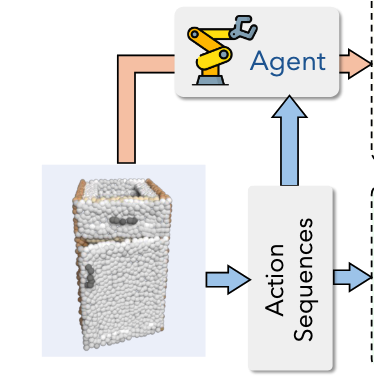
Bhunia, A., Li, C., & Bilen, H. (2025). Interactive Anomaly Detection for Articulated Objects via Motion Anticipation. Neural Information Processing Systems (NeurIPS).
This paper presents a novel problem, interactive anomaly detection (AD) for articulated objects, and introduces a tailored solution that detects functional anomalies by integrating vision, interaction, and anticipation. Unlike traditional AD methods that rely on passive visual observations, our approach actively manipulates objects to reveal anomalies that would otherwise remain hidden. Our method learns to generate a sequence of actions to interact exclusively with normal objects and to anticipate the resulting normal motion. During inference, the model applies predicted actions to the object and compares the observed motion with the anticipated motion to detect anomalies. Additionally, we introduce a new benchmark, PartNet-IAD, for interactive AD, which includes articulated objects with realistic functional anomalies. Experiments show strong generalization to detect anomalies in both seen and unseen object categories. Code and dataset will be released.@inproceedings{Bhunia25a, title = {Interactive Anomaly Detection for Articulated Objects via Motion Anticipation}, author = {Bhunia, Ankan and Li, Changjian and Bilen, Hakan}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2025}, xpdf = {https://openreview.net/pdf?id=t22zHB6yQ0}, xcode = {https://groups.inf.ed.ac.uk/vico/research/interactiveAD/} } -
Danier, D., Aygün, M., Li, C., Bilen, H., & Mac Aodha, O. (2025). DepthCues: Evaluating Monocular Depth Perception in Large Vision Models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Large-scale pre-trained vision models are becoming increasingly prevalent, offering expressive and generalizable visual representations that benefit various downstream tasks. Recent studies on the emergent properties of these models have revealed their high-level geometric understanding, in particular in the context of depth perception. However, it remains unclear how depth perception arises in these models without explicit depth supervision provided during pre-training. To investigate this, we examine whether the monocular depth cues, similar to those used by the human visual system, emerge in these models. We introduce a new benchmark, DepthCues, designed to evaluate depth cue understanding, and present findings across 20 diverse and representative pre-trained vision models. Our analysis shows that human-like depth cues emerge in more recent larger models. We also explore enhancing depth perception in large vision models by fine-tuning on DepthCues, and find that even without dense depth supervision, this improves depth estimation. To support further research, our benchmark and evaluation code will be made publicly available for studying depth perception in vision models.@inproceedings{Danier25, title = {DepthCues: Evaluating Monocular Depth Perception in Large Vision Models}, author = {Danier, Duolikun and Ayg{\"u}n, Mehmet and Li, Changjian and Bilen, Hakan and Mac~Aodha, Oisin}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, xpdf = {https://arxiv.org/pdf/2411.17385}, xcode = {https://danier97.github.io/depthcues} } -

Bhunia, A., Li, C., & Bilen, H. (2025). Odd-One-Out: Anomaly Detection by Comparing with Neighbors. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
This paper introduces a novel anomaly detection (AD) problem that focuses on identifying ’odd-looking’ objects relative to the other instances in a given scene. In contrast to the traditional AD benchmarks, anomalies in our task are scene-specific, defined by the regular instances that make up the majority. Since object instances may be only partly visible from a single viewpoint, our setting employs multiple views of each scene as input. To provide a testbed for future research in this task, we introduce two benchmarks, ToysAD-8K and PartsAD-15K. We propose a novel method that constructs 3D object-centric representations from multiple 2D views for each instance and detects the anomalous ones through a cross-instance comparison. We rigorously analyze our method quantitatively and qualitatively on the presented benchmarks.@inproceedings{Bhunia25, title = {Odd-One-Out: Anomaly Detection by Comparing with Neighbors}, author = {Bhunia, Ankan and Li, Changjian and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, xpdf = {https://arxiv.org/pdf/2406.20099.pdf}, xcode = {https://github.com/VICO-UoE/OddOneOutAD} } -
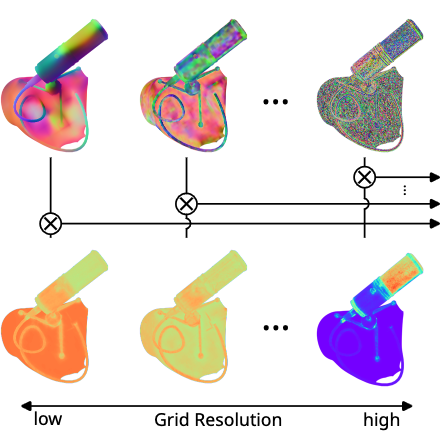
Walker, T., Mariotti, O., Vaxman, A., & Bilen, H. (2025). Spatially-Adaptive Hash Encodings For Neural Surface Reconstruction. IEEE Winter Conference on Applications of Computer Vision (WACV).
Positional encodings are a common component of neural scene reconstruction methods, and provide a way to bias the learning of neural fields towards coarser or finer representations. Current neural surface reconstruction methods use a one-size-fits-all approach to encoding, choosing a fixed set of encoding functions, and therefore bias, across all scenes. Current state-of-the-art surface reconstruction approaches leverage grid-based multi-resolution hash encoding in order to recover high-detail geometry. We propose a learned approach which allows the network to choose its encoding basis as a function of space, by masking the contribution of features stored at separate grid resolutions. The resulting spatially adaptive approach allows the network to fit a wider range of frequencies without introducing noise. We test our approach on standard benchmark surface reconstruction datasets and achieve state-of-the-art performance on two benchmark datasets.@inproceedings{Walker25, title = {Spatially-Adaptive Hash Encodings For Neural Surface Reconstruction}, author = {Walker, Thomas and Mariotti, Octave and Vaxman, Amir and Bilen, Hakan}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, xpdf = {https://arxiv.org/pdf/2412.05179.pdf} }
2024
-
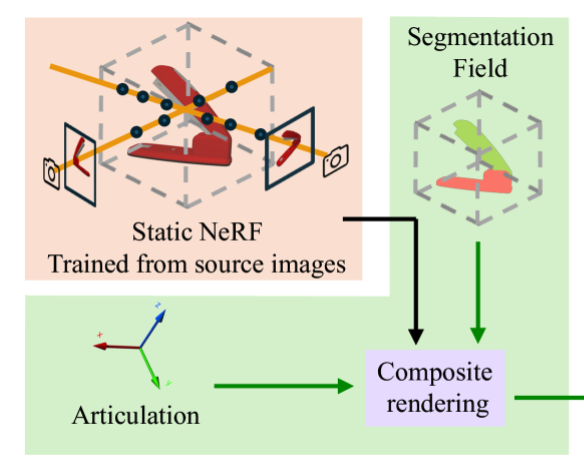
Deng, J., Subr, K., & Bilen, H. (2024). Articulate your NeRF: Unsupervised articulated object modeling via conditional view synthesis. Neural Information Processing Systems (NeurIPS).
We propose a novel unsupervised method to learn the pose and part-segmentation of articulated objects with rigid parts. Given two observations of an object in different articulation states, our method learns the geometry and appearance of object parts by using an implicit model from the first observation, distils the part segmentation and articulation from the second observation while rendering the latter observation. Additionally, to tackle the complexities in the joint optimization of part segmentation and articulation, we propose a voxel grid-based initialization strategy and a decoupled optimization procedure. Compared to the prior unsupervised work, our model obtains significantly better performance, and generalizes to objects with multiple parts while it can be efficiently from few views for the latter observation.@inproceedings{Deng24, title = {Articulate your NeRF: Unsupervised articulated object modeling via conditional view synthesis}, author = {Deng, Jianning and Subr, Kartic and Bilen, Hakan}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2024}, xpdf = {https://arxiv.org/abs/2406.16623}, xcode = {https://github.com/VICO-UoE/ArticulateYourNerf/} } -

Mariotti, O., Mac Aodha, O., & Bilen, H. (2024). Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Recent progress in self-supervised representation learning has resulted in models that are capable of extracting image features that are not only effective at encoding image-level, but also pixel-level, semantics. These features have been shown to be effective for dense visual semantic correspondence estimation, even outperforming fully-supervised methods. Nevertheless, current self-supervised approaches still fail in the presence of challenging image characteristics such as symmetries and repeated parts. To address these limitations, we propose a new approach for semantic correspondence estimation that supplements discriminative self-supervised features with 3D understanding via a weak geometric spherical prior. Compared to more involved 3D pipelines, our model only requires weak viewpoint information, and the simplicity of our spherical representation enables us to inject informative geometric priors into the model during training. We propose a new evaluation metric that better accounts for repeated part and symmetry-induced mistakes. We present results on the challenging SPair-71k dataset, where we show that our approach demonstrates is capable of distinguishing between symmetric views and repeated parts across many object categories, and also demonstrate that we can generalize to unseen classes on the AwA dataset.@inproceedings{Mariotti24, title = {Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps}, author = {Mariotti, Octave and Mac~Aodha, Oisin and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, xpdf = {https://arxiv.org/pdf/2312.13216.pdf}, xcode = {https://github.com/VICO-UoE/SphericalMaps} } -
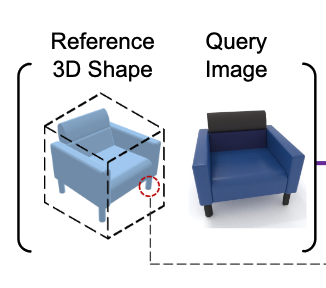
Bhunia, A., Li, C., & Bilen, H. (2024). Looking 3D: Anomaly Detection with 2D-3D Alignment. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Automatic anomaly detection based on visual cues holds practical significance in various domains, such as manufacturing and product quality assessment. This paper introduces a new conditional anomaly detection problem, which involves identifying anomalies in a query image by comparing it to a reference shape. To address this challenge, we have created a large dataset, BrokenChairs-180K, consisting of around 180K images, with diverse anomalies, geometries, and textures paired with 8,143 reference 3D shapes. To tackle this task, we have proposed a novel transformer-based approach that explicitly learns the correspondence between the query image and reference 3D shape via feature alignment and leverages a customized attention mechanism for anomaly detection. Our approach has been rigorously evaluated through comprehensive experiments, serving as a benchmark for future research in this domain.@inproceedings{Bhunia24, title = {Looking 3D: Anomaly Detection with 2D-3D Alignment}, author = {Bhunia, Ankan and Li, Changjian and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, xcode = {https://github.com/VICO-UoE/Looking3D}, xpdf = {https://openaccess.thecvf.com/content/CVPR2024/papers/Bhunia_Looking_3D_Anomaly_Detection_with_2D-3D_Alignment_CVPR_2024_paper.pdf} } -
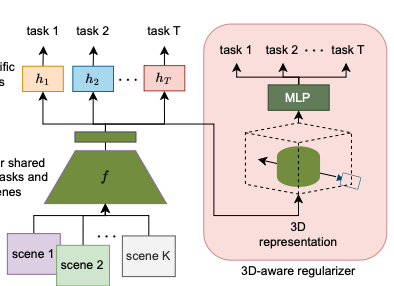
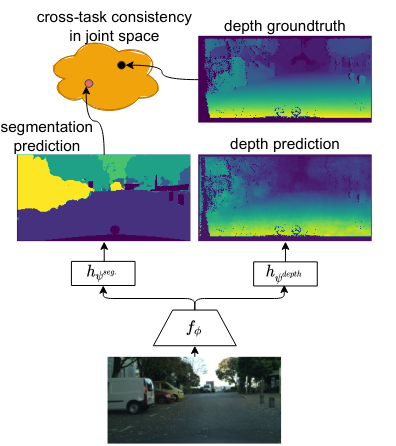
Li, W.-H., McDonagh, S., Leonardis, A., & Bilen, H. (2024). Multi-task Learning with 3D-Aware Regularization. International Conference on Learning Representations (ICLR).
Deep neural networks have become the standard solution for designing models that can perform multiple dense computer vision tasks such as depth estimation and semantic segmentation thanks to their ability to capture complex correlations in high dimensional feature space across tasks. However, the cross-task correlations that are learned in the unstructured feature space can be extremely noisy and susceptible to overfitting, consequently hurting performance. We propose to address this problem by introducing a structured 3D-aware regularizer which interfaces multiple tasks through the projection of features extracted from an image encoder to a shared 3D feature space and decodes them into their task output space through differentiable rendering. We show that the proposed method is architecture agnostic and can be plugged into various prior multi-task backbones to improve their performance; as we evidence using standard benchmarks NYUv2 and PASCAL-Context.@inproceedings{Li24, title = {Multi-task Learning with 3D-Aware Regularization}, author = {Li, Wei-Hong and McDonagh, Steven and Leonardis, Ales and Bilen, Hakan}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2024}, xcode = {https://github.com/VICO-UoE/3DAwareMTL}, xpdf = {https://openreview.net/pdf?id=TwBY17Hgiy} }
2023
-

Mariotti, O. (2023). Unsupervised category-level viewpoint estimation [PhD thesis]. University of Edinburgh.
The recent progress in deep learning techniques transformed the field of computer vision, with tasks like object classification or segmentation being almost considered solved. This however requires sufficiently many labeled samples to train the system, hence research focus has shifted towards tasks where collecting such data is challenging. Recovering camera poses is one such task, where labels are typically too costly for supervised approaches. This work explores solutions to train camera pose estimation systems without the need for external supervision. Preliminary assessments show that it is possible to formulate this problem as a self supervised reconstruction task. By interpreting a network output as 3D rotation, and using this output to control a differentiable rendering operation, gradient descent can be used to train the network to predict viewpoint information. However, multiple issues arise when applying such a method naively on complex data. Confounding factors of particular importance are symmetries, geometry-breaking rendering pipelines and background induced noise. This leads to a regime where purely self-supervised training breaks, al though semi-supervised approaches are still successful. Specific solutions to the aforementioned problems are therefore studied and evaluated. For symmetries, multiple viewpoint predictions are made, and their distribution is further regulated. Two main rendering pipelines are also compared to improve over naive convolution-based reconstruction: a voxel-based one, and a more recent implicit neural representation. Experimental evidence shows that carefully crafting a system with these improvements allows recovery of poses on many everyday objects, such as cars and chairs, with performances reaching the level of supervised approaches on some categories. In addition, this thesis underlines two potential problems in related approaches. First, an unstable pose retrieval method used in recent implicit representations, that is prohibitively expensive. Second, an insidious issue in unsupervised methods, arising from a combination of dataset biases and naive calibration. As this potentially leads to overestimated performances, it calls for a more robust evaluation standard, as well as more careful data gathering.@phdthesis{Mariotti23, title = {Unsupervised category-level viewpoint estimation}, author = {Mariotti, Octave}, school = {University of Edinburgh}, year = {2023}, xpdf = {https://era.ed.ac.uk/handle/1842/40529} } -
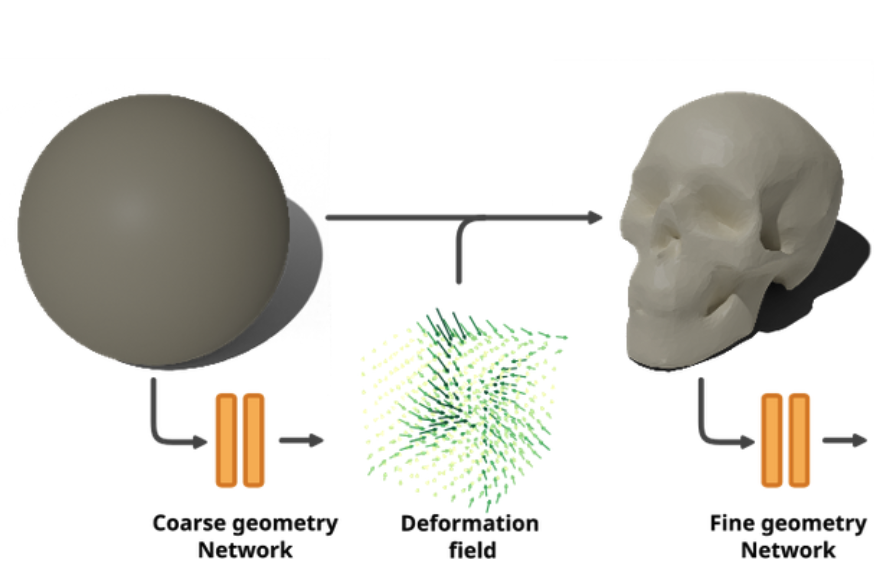
Walker, T., Mariotti, O., Vaxman, A., & Bilen, H. (2023). Explicit Neural Surfaces: Learning Continuous Geometry With Deformation Fields. Neural Information Processing Systems (NeurIPS) Workshop on Symmetry and Geometry in Neural Representations.
We introduce Explicit Neural Surfaces (ENS), an efficient surface reconstruction method that learns an explicitly defined continuous surface from multiple views. We use a series of neural deformation fields to progressively transform a continuous input surface to a target shape. By sampling meshes as discrete surface proxies, we train the deformation fields through efficient differentiable rasterization, and attain a mesh-independent and smooth surface representation. By using Laplace-Beltrami eigenfunctions as an intrinsic positional encoding alongside standard extrinsic Fourier features, our approach can capture fine surface details. ENS trains 1 to 2 orders of magnitude faster and can extract meshes of higher quality compared to implicit representations, whilst maintaining competitive surface reconstruction performance and real-time capabilities. Finally, we apply our approach to learn a collection of objects in a single model, and achieve disentangled interpolations between different shapes, their surface details, and textures.@inproceedings{Walker23, title = {Explicit Neural Surfaces: Learning Continuous Geometry With Deformation Fields}, author = {Walker, Thomas and Mariotti, Octave and Vaxman, Amir and Bilen, Hakan}, booktitle = {Neural Information Processing Systems (NeurIPS) Workshop on Symmetry and Geometry in Neural Representations}, year = {2023}, xpdf = {https://www.pure.ed.ac.uk/ws/portalfiles/portal/412836276/2306.02956v3.pdf} } -
Goel, A. (2023). Investigating the role of linguistic knowledge in vision and language tasks [PhD thesis]. University of Edinburgh.
Artificial Intelligence (AI) has transformed the way we interact with technology e.g. chatbots, voice-based assistants, smart devices and so on. One particular area that has gained tremendous attention and importance is learning through multimodal data sources within AI systems. By incorporating multimodal learning into AI systems, we can bridge the gap between human and machine communication, enabling more intuitive and natural interactions. Multimodal learning is the integration of multiple sensory modalities, such as text, images, speech, and gestures, to enable machines to understand and interpret humans and the world around us more comprehensively. In this thesis we develop strategies to exploit multimodal data (specifically text and images) along with linguistic knowledge, making multimodal systems more reliable and accurate for various vision and language tasks.@phdthesis{Goel23b, title = {Investigating the role of linguistic knowledge in vision and language tasks}, author = {Goel, Arushi}, school = {University of Edinburgh}, year = {2023}, xpdf = {https://era.ed.ac.uk/handle/1842/41215} } -
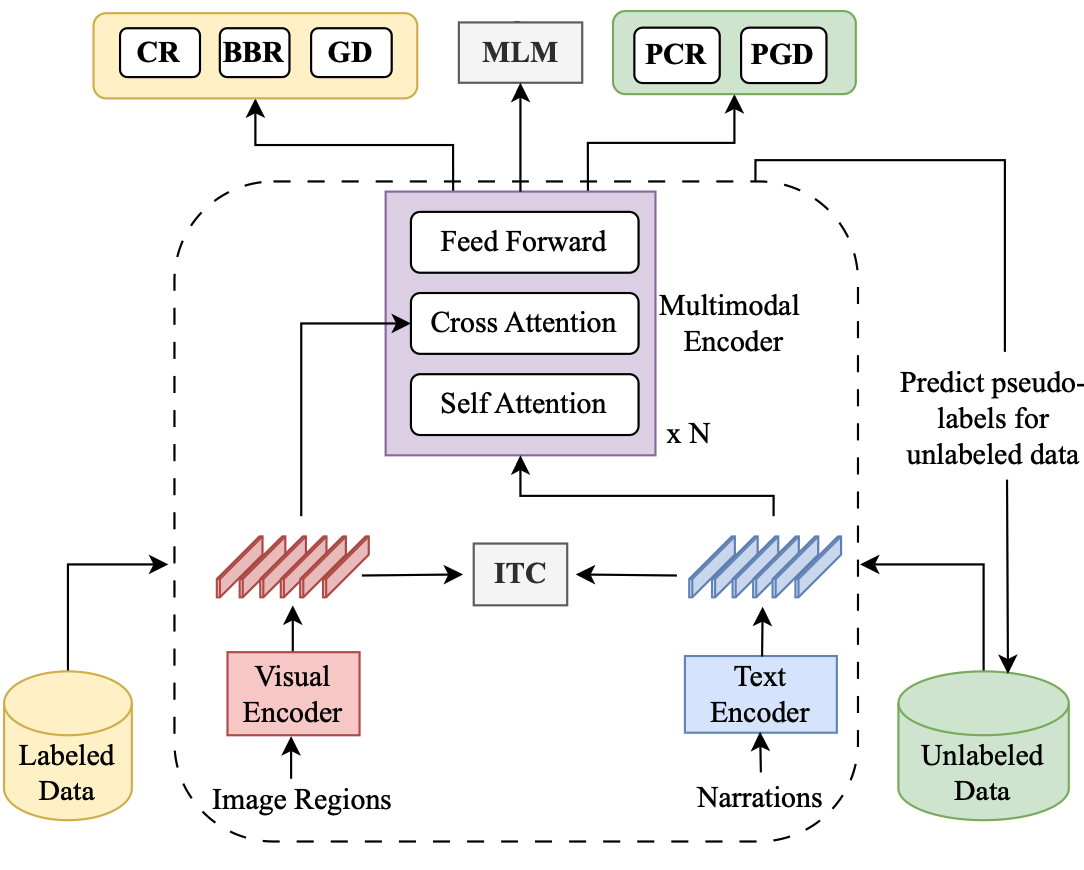
Goel, A., Fernando, B., Keller, F., & Bilen, H. (2023). Semi-supervised multimodal coreference resolution in image narrations. Conference on Empirical Methods in Natural Language Processing (EMNLP).
In this paper, we study multimodal coreference resolution, specifically where a longer descriptive text, i.e., a narration is paired with an image. This poses significant challenges due to fine-grained image-text alignment, inherent ambiguity present in narrative language, and unavailability of large annotated training sets. To tackle these challenges, we present a data efficient semi-supervised approach that utilizes image-narration pairs to resolve coreferences and narrative grounding in a multimodal context. Our approach incorporates losses for both labeled and unlabeled data within a cross-modal framework. Our evaluation shows that the proposed approach outperforms strong baselines both quantitatively and qualitatively, for the tasks of coreference resolution and narrative grounding.@inproceedings{Goel23a, title = {Semi-supervised multimodal coreference resolution in image narrations}, author = {Goel, Arushi and Fernando, Basura and Keller, Frank and Bilen, Hakan}, booktitle = {Conference on Empirical Methods in Natural Language Processing (EMNLP)}, year = {2023}, xcode = {https://github.com/VICO-UoE/CIN-SSL}, xpdf = {https://arxiv.org/pdf/2310.13619.pdf} } -

Goel, A., Fernando, B., Keller, F., & Bilen, H. (2023). Who are you referring to? Coreference resolution in image narrations. IEEE/CVF Conference on Computer Vision (ICCV).
Coreference resolution aims to identify words and phrases which refer to same entity in a text, a core task in natural language processing. In this paper, we extend this task to resolving coreferences in long-form narrations of visual scenes. First we introduce a new dataset with annotated coreference chains and their bounding boxes, as most existing image-text datasets only contain short sentences without coreferring expressions or labeled chains. We propose a new technique that learns to identify coreference chains using weak supervision, only from image-text pairs and a regularization using prior linguistic knowledge. Our model yields large performance gains over several strong baselines in resolving coreferences. We also show that coreference resolution helps improving grounding narratives in images.@inproceedings{Goel23, title = {Who are you referring to? Coreference resolution in image narrations}, author = {Goel, Arushi and Fernando, Basura and Keller, Frank and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision (ICCV)}, year = {2023}, xcode = {https://github.com/VICO-UoE/CIN} } -
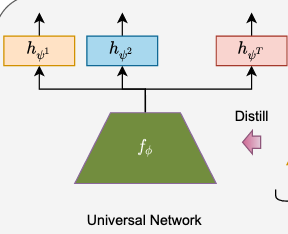
Li, W.-H., Liu, X., & Bilen, H. (2023). Universal Representations: A Unified Look at Multiple Task and Domain Learning. International Journal of Computer Vision (IJCV).
We propose a unified look at jointly learning multiple vision tasks and visual domains through universal representations, a single deep neural network. Learning multiple problems simultaneously involves minimizing a weighted sum of multiple loss functions with different magnitudes and characteristics and thus results in unbalanced state of one loss dominating the optimization and poor results compared to learning a separate model for each problem. To this end, we propose distilling knowledge of multiple task/domain-specific networks into a single deep neural network after aligning its representations with the task/domain-specific ones through small capacity adapters. We rigorously show that universal representations achieve state-of-the-art performances in learning of multiple dense prediction problems in NYU-v2 and Cityscapes, multiple image classification problems from diverse domains in Visual Decathlon Dataset and cross-domain few-shot learning in MetaDataset. Finally we also conduct multiple analysis through ablation and qualitative studies.@article{Li23, title = {Universal Representations: A Unified Look at Multiple Task and Domain Learning}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {International Journal of Computer Vision (IJCV)}, year = {2023}, xcode = {https://github.com/VICO-UoE/UniversalRepresentations}, xpdf = {https://arxiv.org/pdf/2204.02744.pdf} } -

Anciukevicius, T., Xu, Z., Fisher, M., Henderson, P., Bilen, H., Mitra, N. J., & Guerrero, P. (2023). RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Diffusion models currently achieve state-of-the-art performance for both conditional and unconditional image generation. However, so far, image diffusion models do not support tasks required for 3D understanding, such as view-consistent 3D generation or single-view object reconstruction. In this paper, we present RenderDiffusion as the first diffusion model for 3D generation and inference that can be trained using only monocular 2D supervision. At the heart of our method is a novel image denoising architecture that generates and renders an intermediate three-dimensional representation of a scene in each denoising step. This enforces a strong inductive structure into the diffusion process that gives us a 3D consistent representation while only requiring 2D supervision. The resulting 3D representation can be rendered from any viewpoint. We evaluate RenderDiffusion on ShapeNet and Clevr datasets and show competitive performance for generation of 3D scenes and inference of 3D scenes from 2D images. Additionally, our diffusion-based approach allows us to use 2D inpainting to edit 3D scenes. We believe that our work promises to enable full 3D generation at scale when trained on massive image collections, thus circumventing the need to have large-scale 3D model collections for supervision.@inproceedings{Anciukevicius23, title = {{RenderDiffusion}: Image Diffusion for {3D} Reconstruction, Inpainting and Generation}, author = {Anciukevicius, Titas and Xu, Zexiang and Fisher, Matthew and Henderson, Paul and Bilen, Hakan and Mitra, Niloy J. and Guerrero, Paul}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2023}, xcode = {https://github.com/Anciukevicius/RenderDiffusion}, xpdf = {https://openaccess.thecvf.com/content/CVPR2023/papers/Anciukevicius_RenderDiffusion_Image_Diffusion_for_3D_Reconstruction_Inpainting_and_Generation_CVPR_2023_paper.pdf} } -

Moltisanti, D., Keller, F., Bilen, H., & Sevilla-Lara, L. (2023). Learning Action Changes by Measuring Verb-Adverb Textual Relationships. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
The goal of this work is to understand the way actions are performed in videos. That is, given a video, we aim to predict an adverb indicating a modification applied to the action (e.g. cut “finely”). We cast this problem as a regression task. We measure textual relationships between verbs and adverbs to generate a regression target representing the action change we aim to learn.We test our approach on a range of datasets and achieve state-of-the-art results on both adverb prediction and antonym classification.Furthermore, we outperform previous work when we lift two commonly assumed conditions: the availability of action labels during testing and the pairing of adverbs as antonyms. Existing datasets for adverb recognition are either noisy, which makes learning difficult, or contain actions whose appearance is not influenced by adverbs, which makes evaluation less reliable.To address this, we collect a new high quality dataset: Adverbs in Recipes (AIR). We focus on instructional recipes videos, curating a set of actions that exhibit meaningful visual changes when performed differently. Videos in AIR are more tightly trimmed and were manually reviewed by multiple annotators to ensure high labelling quality.Results show that models learn better from AIR given its cleaner videos. At the same time, adverb prediction on AIR is challenging, demonstrating that there is considerable room for improvement.@inproceedings{Moltisanti23, title = {Learning Action Changes by Measuring Verb-Adverb Textual Relationships}, author = {Moltisanti, Davide and Keller, Frank and Bilen, Hakan and Sevilla-Lara, Laura}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2023}, xcode = {https://github.com/dmoltisanti/air-cvpr23}, xpdf = {https://openaccess.thecvf.com/content/CVPR2023/papers/Moltisanti_Learning_Action_Changes_by_Measuring_Verb-Adverb_Textual_Relationships_CVPR_2023_paper.pdf} } -
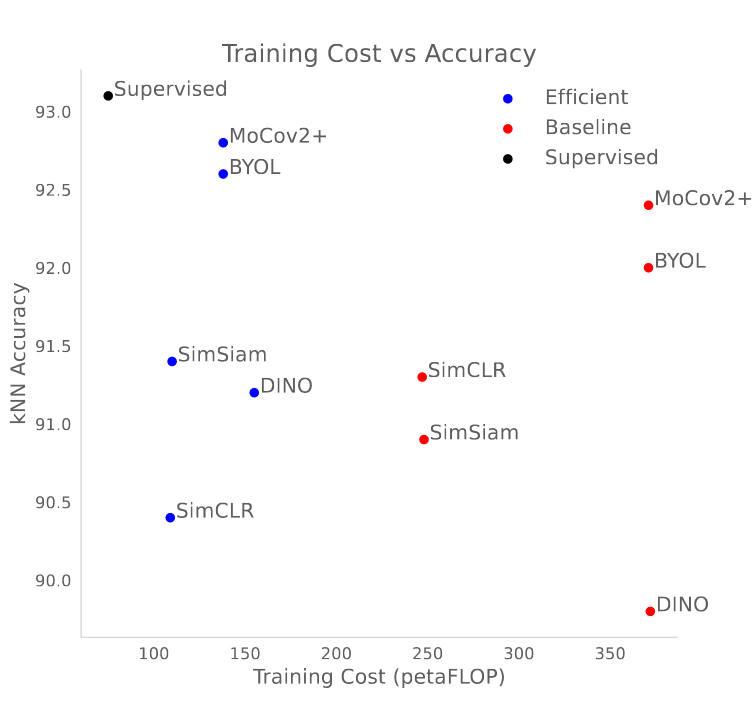
Koçyiğit, M. T., Hospedales, T., & Bilen, H. (2023). Accelerating Self-Supervised Learning via Efficient Training Strategies. IEEE Winter Conference on Applications of Computer Vision (WACV).
Recently the focus of the computer vision community has shifted from expensive supervised learning towards self-supervised learning of visual representations. While the performance gap between supervised and self-supervised has been narrowing, the time for training self-supervised deep networks remains an order of magnitude larger than its supervised counterparts, which hinders progress, imposes carbon cost, and limits societal benefits to institutions with substantial resources. Motivated by these issues, this paper investigates reducing the training time of recent self-supervised methods by various model-agnostic strategies that have not been used for this problem. In particular, we study three strategies: an extendable cyclic learning rate schedule, a matching progressive augmentation magnitude and image resolutions schedule, and a hard positive mining strategy based on augmentation difficulty. We show that all three methods combined lead up to 2.7 times speed-up in the training time of several self-supervised methods while retaining comparable performance to the standard self-supervised learning setting.@inproceedings{Kocyigit23, title = {Accelerating Self-Supervised Learning via Efficient Training Strategies}, author = {Koçyiğit, Mustafa~Taha and Hospedales, Timothy and Bilen, Hakan}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2023} } -
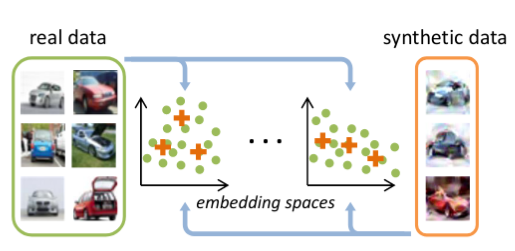
Zhao, B., & Bilen, H. (2023). Dataset condensation with distribution matching. IEEE Winter Conference on Applications of Computer Vision (WACV).
Computational cost of training state-of-the-art deep models in many learning problems is rapidly increasing due to more sophisticated models and larger datasets. A recent promising direction for reducing training cost is dataset condensation that aims to replace the original large training set with a significantly smaller learned synthetic set while preserving the original information. While training deep models on the small set of condensed images can be extremely fast, their synthesis remains computationally expensive due to the complex bi-level optimization and second-order derivative computation. In this work, we propose a simple yet effective method that synthesizes condensed images by matching feature distributions of the synthetic and original training images in many sampled embedding spaces. Our method significantly reduces the synthesis cost while achieving comparable or better performance. Thanks to its efficiency, we apply our method to more realistic and larger datasets with sophisticated neural architectures and obtain a significant performance boost. We also show promising practical benefits of our method in continual learning and neural architecture search.@inproceedings{Zhao23, title = {Dataset condensation with distribution matching}, author = {Zhao, Bo and Bilen, Hakan}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2023}, xcode = {https://github.com/vico-uoe/DatasetCondensation} }
2022
-
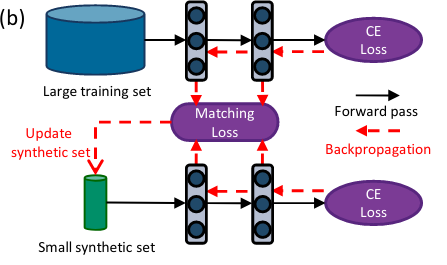
Zhao, B. (2022). Data-efficient neural network training with dataset condensation [PhD thesis]. University of Edinburgh.
The state of the art in many data driven fields including computer vision and natural language processing typically relies on training larger models on bigger data. It is reported by OpenAI that the computational cost to achieve the state of the art doubles every 3.4 months in the deep learning era. In contrast, the GPU computation power doubles every 21.4 months, which is significantly slower. Thus, advancing deep learning performance by consuming more hardware resources is not sustainable. How to reduce the training cost while preserving the generalization performance is a long standing goal in machine learning. This thesis investigates a largely under-explored while promising solution - dataset condensation which aims to condense a large training set into a small set of informative synthetic samples for training deep models and achieve close performance to models trained on the original dataset. In this thesis, we investigate how to condense image datasets for classification tasks. We propose three methods for image dataset condensation. Our methods can be applied to condense other kinds of datasets for different learning tasks, such as text data, graph data and medical images, and we discuss it in Section 6.1.@phdthesis{Zhao22, title = {Data-efficient neural network training with dataset condensation}, author = {Zhao, Bo}, school = {University of Edinburgh}, year = {2022}, xpdf = {https://era.ed.ac.uk/handle/1842/39756} } -
Mariotti, O., Mac Aodha, O., & Bilen, H. (2022). ViewNeRF: Unsupervised Viewpoint Estimation Using Category-Level Neural Radiance Fields. British Machine Vision Conference (BMVC).
We introduce ViewNeRF, a Neural Radiance Field-based viewpoint estimation method that learns to predict category-level viewpoints directly from images during training. While NeRF is usually trained with ground-truth camera poses, multiple extensions have been proposed to reduce the need for this expensive supervision. Nonetheless, most of these methods still struggle in complex settings with large camera movements, and are restricted to single scenes, i.e. they cannot be trained on a collection of scenes depicting the same object category. To address this issue, our method uses an analysis by synthesis approach, combining a conditional NeRF with a viewpoint predictor and a scene encoder in order to produce self-supervised reconstructions for whole object categories. Rather than focusing on high fidelity reconstruction, we target efficient and accurate viewpoint prediction in complex scenarios, e.g. 360 degree rotation on real data. Our model shows competitive results on synthetic and real datasets, both for single scenes and multi-instance collections.@inproceedings{Mariotti22, title = {ViewNeRF: Unsupervised Viewpoint Estimation Using Category-Level Neural Radiance Fields}, author = {Mariotti, Octave and Mac~Aodha, Oisin and Bilen, Hakan}, booktitle = {British Machine Vision Conference (BMVC)}, year = {2022}, xcode = {https://github.com/omariott/viewnerf} } -
Yang, Y., Cheng, X., Liu, C., Bilen, H., & Ji, X. (2022). Distilling Representations from GAN Generator via Squeeze and Span. Neural Information Processing Systems (NeurIPS).
In recent years, generative adversarial networks (GANs) have been an actively studied topic and shown to successfully produce high-quality realistic images in various domains. The controllable synthesis ability of GAN generators suggests that they maintain informative, disentangled, and explainable image representations, but leveraging and transferring their representations to downstream tasks is largely unexplored. In this paper, we propose to distill knowledge from GAN generators by squeezing and spanning their representations. We squeeze the generator features into representations that are invariant to semantic-preserving transformations through a network before they are distilled into the student network. We span the distilled representation of the synthetic domain to the real domain by also using real training data to remedy the mode collapse of GANs and boost the student network performance in a real domain. Experiments justify the efficacy of our method and reveal its great significance in self-supervised representation learning. Code will be made public.@inproceedings{Yang22b, title = {Distilling Representations from GAN Generator via Squeeze and Span}, author = {Yang, Yu and Cheng, Xaiotian and Liu, Chang and Bilen, Hakan and Ji, Xiangyang}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2022} } -
Li, W.-H. (2022). Learning universal representations across tasks and domains [PhD thesis]. University of Edinburgh.
A longstanding goal in computer vision research is to produce broad and general-purpose systems that work well on a broad range of vision problems and are capable of learning concepts only from few labelled samples. In contrast, existing models are limited to work only in specific tasks or domains (datasets), e.g., a semantic segmentation model for indoor images (Silberman et al., 2012). In addition, they are data inefficient and require large labelled dataset for each task or domain. While there has been works proposed for domain/task-agnostic representations by either loss balancing strategies or architecture design, it remains a challenging problem on optimizing such universal representation network. This thesis focuses on addressing the challenges of learning universal representations that generalize well over multiple tasks (e.g. segmentation, depth estimation) or various visual domains (e.g. image object classification, image action classification). In addition, the thesis also shows that these representations can be learned from partial supervision and transferred and adopted to previously unseen tasks/domains in data-efficient manner.@phdthesis{Li22b, title = {Learning universal representations across tasks and domains}, author = {Li, Wei-Hong}, school = {University of Edinburgh}, year = {2022}, xpdf = {https://hdl.handle.net/1842/39625} } -
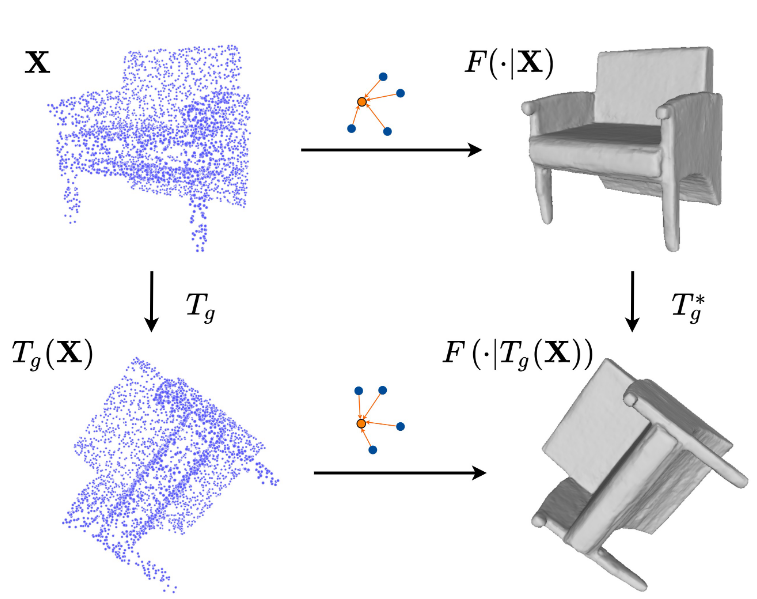
Chen, Y., Fernando, B., Bilen, H., Nießner, M., & Gavves, E. (2022). 3D Equivariant Graph Implicit Functions. European Conference on Computer Vision (ECCV).
In recent years, neural implicit representations have made remarkable progress in modeling of 3D shapes with arbitrary topology.In this work, we address two key limitations of such representations, in failing to capture local 3D geometric fine details, and to learn from and generalize to shapes with unseen 3D transformations. To this end, we introduce a novel family of graph implicit functions with equivariant layers that facilitates modeling fine local details and guaranteed robustness to various groups of geometric transformations, through local k-NN graph embeddings with sparse point set observations at multiple resolutions.Our method improves over the existing rotation-equivariant implicit function from 0.69 to 0.89 (IoU) on the ShapeNet reconstruction task. We also show that our equivariant implicit function can be extended to other types of similarity transformations and generalizes to unseen translations and scaling.@inproceedings{Chen22, title = {3D Equivariant Graph Implicit Functions}, author = {Chen, Yunlu and Fernando, Basura and Bilen, Hakan and Nie{\ss}ner, Matthias and Gavves, Efstratios}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2022} } -
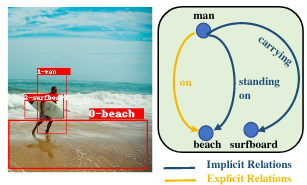
Goel, A., Fernando, B., Keller, F., & Bilen, H. (2022). Not All Relations are Equal: Mining Informative Labels for Scene Graph Generation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Scene graph generation (SGG) aims to capture a wide variety of interactions between pairs of objects, which is essential for full scene understanding. Existing SGG methods trained on the entire set of relations fail to acquire complex reasoning about visual and textual correlations due to various biases in training data. Learning on trivial relations that indicate generic spatial configuration like ’on’ instead of informative relations such as ’parked on’ does not enforce this complex reasoning, harming generalization. To address this problem, we propose a novel framework for SGG training that exploits relation labels based on their informativeness. Our model-agnostic training procedure imputes missing informative relations for less informative samples in the training data and trains a SGG model on the imputed labels along with existing annotations. We show that this approach can successfully be used in conjunction with state-of-the-art SGG methods and improves their performance significantly in multiple metrics on the standard Visual Genome benchmark. Furthermore, we obtain considerable improvements for unseen triplets in a more challenging zero-shot setting.@inproceedings{Goel22, title = {Not All Relations are Equal: Mining Informative Labels for Scene Graph Generation}, author = {Goel, Arushi and Fernando, Basura and Keller, Frank and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } -
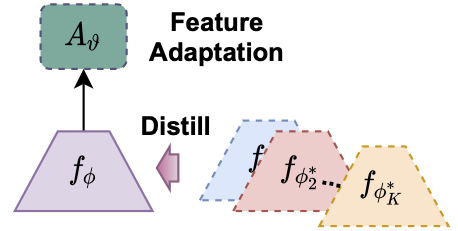
Li, W.-H., Liu, X., & Bilen, H. (2022). Learning Multiple Dense Prediction Tasks from Partially Annotated Data. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Despite the recent advances in multi-task learning of dense prediction problems, most methods rely on expensive labelled datasets. In this paper, we present a label efficient approach and look at jointly learning of multiple dense prediction tasks on partially annotated data, which we call multi-task partially-supervised learning. We propose a multi-task training procedure that successfully leverages task relations to supervise its multi-task learning when data is partially annotated. In particular, we learn to map each task pair to a joint pairwise task-space which enables sharing information between them in a computationally efficient way through another network conditioned on task pairs, and avoids learning trivial cross-task relations by retaining high-level information about the input image. We rigorously demonstrate that our proposed method effectively exploits the images with unlabelled tasks and outperforms existing semi-supervised learning approaches and related methods on three standard benchmarks.@inproceedings{Li22, title = {Learning Multiple Dense Prediction Tasks from Partially Annotated Data}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } -
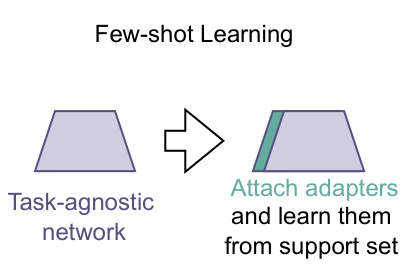
Li, W.-H., Liu, X., & Bilen, H. (2022). Cross-domain Few-shot Learning with Task-specific Adapters. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
In this paper, we look at the problem of cross-domain few-shot classification that aims to learn a classifier from previously unseen classes and domains with few labeled samples. We study several strategies including various adapter topologies and operations in terms of their performance and efficiency that can be easily attached to existing methods with different meta-training strategies and adapt them for a given task during meta-test phase. We show that parametric adapters attached to convolutional layers with residual connections performs the best, and significantly improves the performance of the state-of-the-art models in the Meta-Dataset benchmark with minor additional cost.@inproceedings{Li22a, title = {Cross-domain Few-shot Learning with Task-specific Adapters}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, xcode = {https://github.com/VICO-UoE/URL} } -
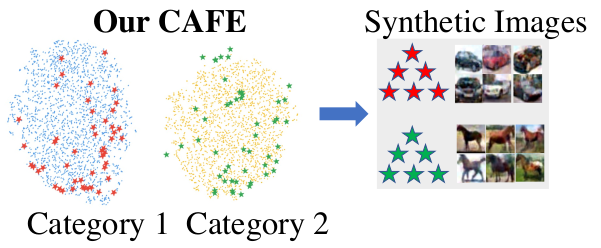
Wang, K., Zhao, B., Peng, X., Zhu, Z., Yang, S., Wang, S., Huang, G., Bilen, H., Wang, X., & You, Y. (2022). CAFE: Learning to Condense Dataset by Aligning Features. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
Dataset condensation aims at reducing the network training effort through condensing a cumbersome training set into a compact synthetic one. State-of-the-art approaches largely rely on learning the synthetic data by matching the gradients between the real and synthetic data batches. Despite the intuitive motivation and promising results, such gradient-based methods, by nature, easily overfit to a biased set of samples that produce dominant gradients, and thus lack a global supervision of data distribution. In this paper, we propose a novel scheme to Condense dataset by Aligning FEatures (CAFE), which explicitly attempts to preserve the real-feature distribution as well as the discriminant power of the resulting synthetic set, lending itself to strong generalization capability to various architectures. At the heart of our approach is an effective strategy to align features from the real and synthetic data across various scales, while accounting for the classification of real samples. Our scheme is further backed up by a novel dynamic bi-level optimization, which adaptively adjusts parameter updates to prevent over-/under-fitting. We validate the proposed CAFE across various datasets, and demonstrate that it generally outperforms the state of the art: on the SVHN dataset, for example, the performance gain is up to 11%. Extensive experiments and analysis verify the effectiveness and necessity of proposed designs@inproceedings{Wang22, title = {CAFE: Learning to Condense Dataset by Aligning Features}, author = {Wang, Kai and Zhao, Bo and Peng, Xiangyu and Zhu, Zheng and Yang, Shuo and Wang, Shuo and Huang, Guan and Bilen, Hakan and Wang, Xinchao and You, Yang}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022} } -
Deecke, L. (2022). Image Classification over Unknown and Anomalous Domains [PhD thesis]. University of Edinburgh.
A longstanding goal in computer vision research is to produce broad and general-purpose systems that work well on a broad range of vision problems and are capable of learning concepts only from few labelled samples. In contrast, existing models are limited to work only in specific tasks or domains (datasets), e.g., a semantic segmentation model for indoor images (Silberman et al., 2012). In addition, they are data inefficient and require large labelled dataset for each task or domain. While there has been works proposed for domain/task-agnostic representations by either loss balancing strategies or architecture design, it remains a challenging problem on optimizing such universal representation network. This thesis focuses on addressing the challenges of learning universal representations that generalize well over multiple tasks (e.g. segmentation, depth estimation) or various visual domains (e.g. image object classification, image action classification). In addition, the thesis also shows that these representations can be learned from partial supervision and transferred and adopted to previously unseen tasks/domains in data-efficient manner.@phdthesis{Deecke22a, title = {Image Classification over Unknown and Anomalous Domains}, author = {Deecke, Lucas}, school = {University of Edinburgh}, year = {2022}, xpdf = {http://dx.doi.org/10.7488/era/2019} } -
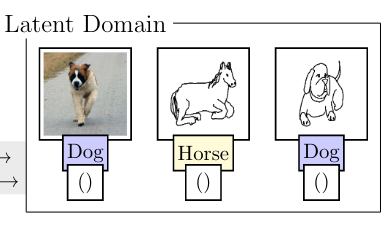
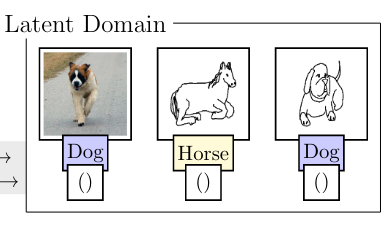
Deecke, L., Hospedales, T., & Bilen, H. (2022). Visual Representation Learning over Latent Domains. International Conference on Learning Representations (ICLR).
A fundamental shortcoming of deep neural networks is their specialization to a single task and domain. While multi-domain learning enables the learning of compact models that span multiple visual domains, these rely on the presence of domain labels, in turn requiring laborious curation of datasets. This paper proposes a less explored, but highly realistic new setting called latent domain learning: learning over data from different domains, without access to domain annotations. Experiments show that this setting is particularly challenging for standard models and existing multi-domain approaches, calling for new customized solutions: a sparse adaptation strategy is formulated which adaptively accounts for latent domains in data, and significantly enhances learning in such settings. Our method can be paired seamlessly with existing models, and boosts performance in conceptually related tasks, eg empirical fairness problems and long-tailed recognition.@inproceedings{Deecke22, title = {Visual Representation Learning over Latent Domains}, author = {Deecke, Lucas and Hospedales, Timothy and Bilen, Hakan}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2022}, xcode = {https://github.com/VICO-UoE/LatentDomainLearning} } -
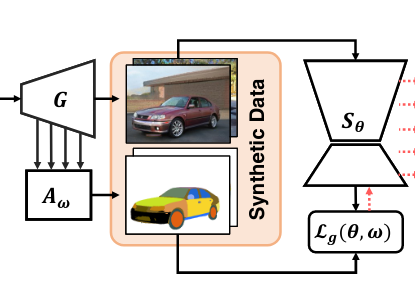
Yang, Y., Cheng, X., Bilen, H., & Ji, X. (2022). Learning to Annotate Part Segmentation with Gradient Matching. International Conference on Learning Representations (ICLR).
The success of state-of-the-art deep neural networks heavily relies on the presence of large-scale labeled datasets, which are extremely expensive and time-consuming to annotate. This paper focuses on reducing the annotation cost of part segmentation by generating high-quality images with a pre-trained GAN and labeling the generated images with an automatic annotator. In particular, we formulate the annotator learning as the following learning-to-learn problem. Given a pre-trained GAN, the annotator learns to label object parts in a set of randomly generated images such that a part segmentation model trained on these synthetic images with automatic labels obtains superior performance evaluated on a small set of manually labeled images. We show that this nested-loop optimization problem can be reduced to a simple gradient matching problem, which is further efficiently solved with an iterative algorithm. As our method suits the semi-supervised learning setting, we evaluate our method on semi-supervised part segmentation tasks. Experiments demonstrate that our method significantly outperforms other semi-supervised competitors, especially when the amount of labeled examples is limited.@inproceedings{Yang22a, title = {Learning to Annotate Part Segmentation with Gradient Matching}, author = {Yang, Yu and Cheng, Xiaotian and Bilen, Hakan and Ji, Xiangyang}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2022} } -

Yang, Y., Bilen, H., Zou, Q., Cheung, W. Y., & Ji, X. (2022). Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs. IEEE Winter Conference on Applications of Computer Vision (WACV).
We propose an unsupervised foreground-background segmentation method via training a segmentation network on the synthetic pseudo segmentation dataset generated from GANs, which are trained from a collection of images without annotations to explicitly disentangle foreground and background. To efficiently generate foreground and background layers and overlay them to compose novel images, the construction of such GANs is fulfilled by our proposed Equivariant Layered GAN, whose improvement, compared to the precedented layered GAN, is embodied in the following two aspects. (1) The disentanglement of foreground and background is improved by extending the previous perturbation strategy and introducing private code recovery that reconstructs the private code of foreground from the composite image. (2) The latent space of the layered GANs is regularized by minimizing our proposed equivariance loss, resulting in interpretable latent codes and better disentanglement of foreground and background. Our methods are evaluated on unsupervised object segmentation datasets including Caltech-UCSD Birds and LSUN Car, achieving state-of-the-art performance.@inproceedings{Yang22, title = {Unsupervised Foreground-Background Segmentation with Equivariant Layered GANs}, author = {Yang, Yu and Bilen, Hakan and Zou, Qiran and Cheung, Wing Yin and Ji, Xiangyang}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2022} }
2021
-
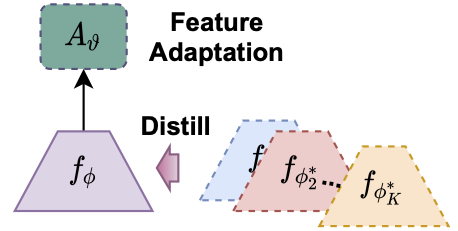
Li, W.-H., Liu, X., & Bilen, H. (2021). Universal Representation Learning from Multiple Domains for Few-shot Classification. International Conference on Computer Vision (ICCV).
In this paper, we look at the problem of few-shot classification that aims to learn a classifier for previously unseen classes and domains from few labeled samples. Recent methods use adaptation networks for aligning their features to new domains or select the relevant features from multiple domain-specific feature extractors. In this work, we propose to learn a single set of universal deep representations by distilling knowledge of multiple separately trained networks after co-aligning their features with the help of adapters and centered kernel alignment. We show that the universal representations can be further refined for previously unseen domains by an efficient adaptation step in a similar spirit to distance learning methods. We rigorously evaluate our model in the recent Meta-Dataset benchmark and demonstrate that it significantly outperforms the previous methods while being more efficient.@inproceedings{Li21, title = {Universal Representation Learning from Multiple Domains for Few-shot Classification}, author = {Li, Wei-Hong and Liu, Xialei and Bilen, Hakan}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2021}, xcode = {https://github.com/VICO-UoE/URL} } -
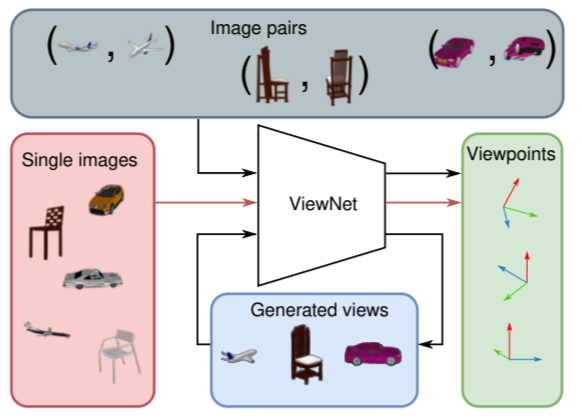
Mariotti, O., Mac Aodha, O., & Bilen, H. (2021). ViewNet: Unsupervised Viewpoint Estimation From Conditional Generation. International Conference on Computer Vision (ICCV).
Understanding the 3D world without supervision is currently a major challenge in computer vision as the annotations required to supervise deep networks for tasks in this domain are expensive to obtain on a large scale.In this paper, we address the problem of unsupervised viewpoint estimation. We formulate this as a self-supervised learning task, where image reconstruction from raw images provides the supervision needed to predict camera viewpoint. Specifically, we make use of pairs of images of the same object at training time, from unknown viewpoints, to self-supervise training by combining the viewpoint information from one image with the appearance information from the other. We demonstrate that using a perspective spatial transformer allows efficient viewpoint learning, outperforming existing unsupervised approaches on synthetic data and obtaining competitive results on the challenging PASCAL3D+.@inproceedings{Mariotti21, title = {ViewNet: Unsupervised Viewpoint Estimation From Conditional Generation}, author = {Mariotti, Octave and Mac~Aodha, Oisin and Bilen, Hakan}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2021} } -

Chen, Y., Fernando, B., Bilen, H., Mensink, T., & Gavves, E. (2021). Shape Transformation with Deep Implicit Functions by Matching Implicit Features. International Conference on Machine Learning (ICML).
Recently , neural implicit functions have achieved impressive results for encoding 3D shapes. Conditioning on low-dimensional latent codes generalises a single implicit function to learn shared representation space for a variety of shapes, with the advantage of smooth interpolation. While the benefits from the global latent space do not correspond to explicit points at local level, we propose to track the continuous point trajectory by matching implicit features with the latent code interpolating between shapes, from which we corroborate the hierarchical functionality of the deep implicit functions, where early layers map the latent code to fitting the coarse shape structure, and deeper layers further refine the shape details. Furthermore, the structured representation space of implicit functions enables to apply feature matching for shape deformation, with the benefits to handle topology and semantics inconsistency, such as from an armchair to a chair with no arms, without explicit flow functions or manual annotations.@inproceedings{Chen21, title = {Shape Transformation with Deep Implicit Functions by Matching Implicit Features}, author = {Chen, Yunlu and Fernando, Basura and Bilen, Hakan and Mensink, Thomas and Gavves, Efstratios}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021} } -
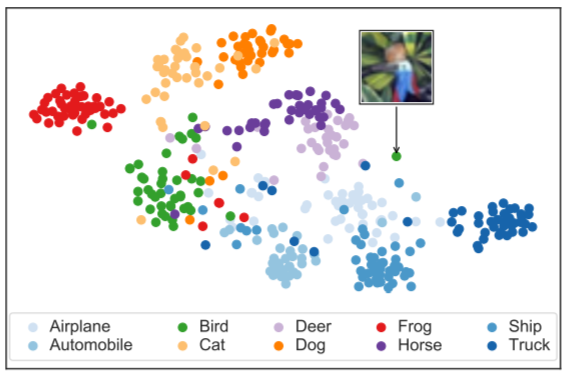
Deecke, L., Ruff, L., Vandermeulen, R. A., & and Bilen, H. (2021). Transfer Based Semantic Anomaly Detection. International Conference on Machine Learning (ICML).
Detecting semantic anomalies is challenging due to the countless ways in which they may appear in real-world data. While enhancing the robustness of networks may be sufficient for modeling simplistic anomalies, there is no good known way of preparing models for all potential and unseen anomalies that can potentially occur, such as the appearance of new object classes. In this paper, we show that a previously overlooked strategy for anomaly detection (AD) is to introduce an explicit inductive bias toward representations transferred over from some large and varied semantic task. We rigorously verify our hypothesis in controlled trials that utilize intervention, and show that it gives rise to surprisingly effective auxiliary objectives that outperform previous AD paradigms.@inproceedings{Deecke21, title = {Transfer Based Semantic Anomaly Detection}, author = {Deecke, Lucas and Ruff, Lucas and Vandermeulen, Robert~A. and and Bilen, Hakan}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021}, xcode = {https://github.com/VICO-UoE/TransferAD} } -
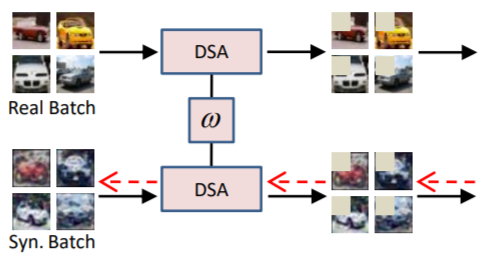
Zhao, B., & Bilen, H. (2021). Dataset Condensation with Differentiable Siamese Augmentation. International Conference on Machine Learning (ICML).
In many machine learning problems, large-scale datasets have become the de-facto standard to train state-of-the-art deep networks at the price of heavy computation load. In this paper, we focus on condensing large training sets into significantly smaller synthetic sets which can be used to train deep neural networks from scratch with minimum drop in performance. Inspired from the recent training set synthesis methods, we propose Differentiable Siamese Augmentation that enables effective use of data augmentation to synthesize more informative synthetic images and thus achieves better performance when training networks with augmentations. Experiments on multiple image classification benchmarks demonstrate that the proposed method obtains substantial gains over the state-of-the-art, 7% improvements on CIFAR10 and CIFAR100 datasets. We show with only less than 1% data that our method achieves 99.6%, 94.9%, 88.5%, 71.5% relative performance on MNIST, FashionMNIST, SVHN, CIFAR10 respectively. We also explore the use of our method in continual learning and neural architecture search, and show promising results.@inproceedings{Zhao21a, title = {Dataset Condensation with Differentiable Siamese Augmentation}, author = {Zhao, Bo and Bilen, Hakan}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021}, xcode = {https://github.com/vico-uoe/DatasetCondensation} } -
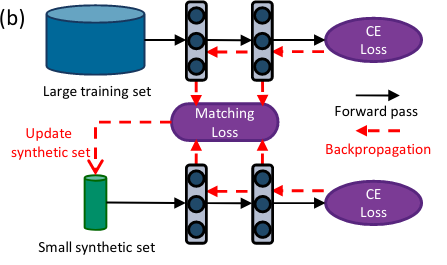
Zhao, B., Konda, R. M., & Bilen, H. (2021). Dataset Condensation with Gradient Matching. International Conference on Learning Representations (ICLR).
As the state-of-the-art machine learning methods in many fields rely on larger datasets, storing datasets and training models on them become significantly more expensive. This paper proposes a training set synthesis technique for data-efficient learning, called Dataset Condensation, that learns to condense large dataset into a small set of informative synthetic samples for training deep neural networks from scratch. We formulate this goal as a gradient matching problem between the gradients of deep neural network weights that are trained on the original and our synthetic data. We rigorously evaluate its performance in several computer vision benchmarks and demonstrate that it significantly outperforms the state-of-the-art methods. Finally we explore the use of our method in continual learning and neural architecture search and report promising gains when limited memory and computations are available.@inproceedings{Zhao21, title = {Dataset Condensation with Gradient Matching}, author = {Zhao, Bo and Konda, Reddy~Mopuri and Bilen, Hakan}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2021}, xcode = {https://github.com/vico-uoe/DatasetCondensation} }
2020
-
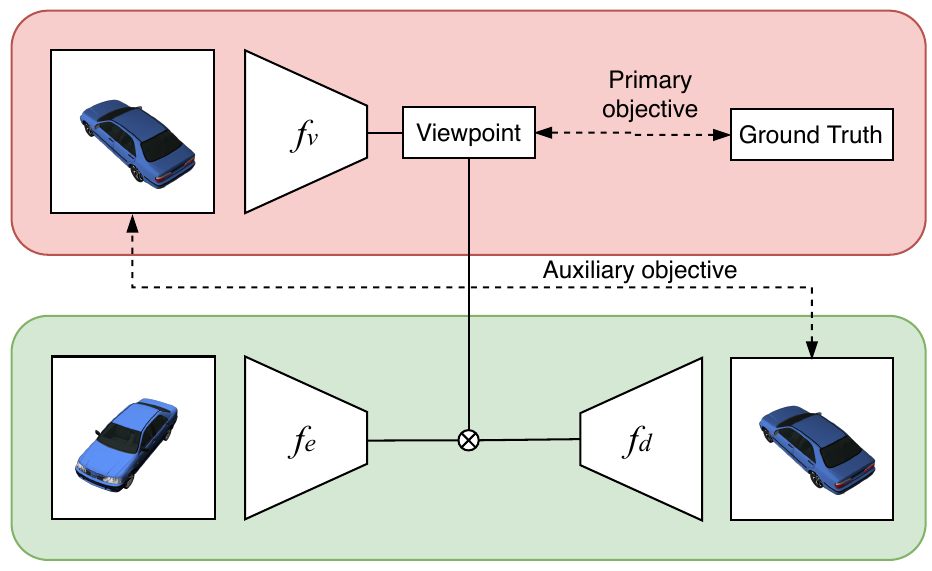
Mariotti, O., & Bilen, H. (2020). Semi-supervised Viewpoint Estimation with Geometry-aware Conditional Generation. European Conference on Computer Vision (ECCV) Workshop.
There is a growing interest in developing computer vision methods that can learn from limited supervision. In this paper, we consider the problem of learning to predict camera viewpoints, where obtaining ground-truth annotations are expensive and require special equipment, from a limited number of labeled images. We propose a semisupervised viewpoint estimation method that can learn to infer viewpoint information from unlabeled image pairs, where two images differ by a viewpoint change. In particular our method learns to synthesize the second image by combining the appearance from the first one and viewpoint from the second one. We demonstrate that our method significantly improves the supervised techniques, especially in the low-label regime and outperforms the state-of-the-art semi-supervised methods.@inproceedings{Mariotti20, title = {Semi-supervised Viewpoint Estimation with Geometry-aware Conditional Generation}, author = {Mariotti, Octave and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV) Workshop}, year = {2020}, xcode = {https://github.com/VICO-UoE/SemiSupViewNet} } -
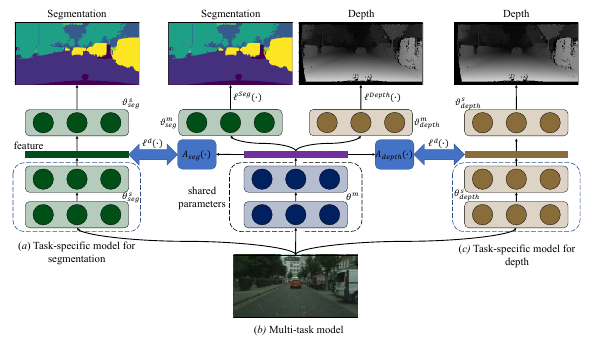
Li, W.-H., & Bilen, H. (2020). Knowledge Distillation for Multi-task Learning. European Conference on Computer Vision (ECCV) Workshop.
Multi-task learning (MTL) is to learn one single model that performs multiple tasks for achieving good performance on all tasks and lower cost on computation. Learning such a model requires to jointly optimize losses of a set of tasks with different difficulty levels, magnitudes, and characteristics (e.g. cross-entropy, Euclidean loss), leading to the imbalance problem in multi-task learning. To address the imbalance problem, we propose a knowledge distillation based method in this work. We first learn a task-specific model for each task. We then learn the multitask model for minimizing task-specific loss and for producing the same feature with task-specific models. As the task-specific network encodes different features, we introduce small task-specific adaptors to project multi-task features to the task-specific features. In this way, the adaptors align the task-specific feature and the multi-task feature, which enables a balanced parameter sharing across tasks. Extensive experimental results demonstrate that our method can optimize a multi-task learning model in a more balanced way and achieve better overall performance.@inproceedings{Li20, title = {Knowledge Distillation for Multi-task Learning}, author = {Li, Wei-Hong and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV) Workshop}, year = {2020}, xcode = {https://github.com/VICO-UoE/KD4MTL} } -
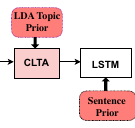
Goel, A., Fernando, B., Nguyen, T.-S., & Bilen, H. (2020). Injecting Prior Knowledge into Image Captioning. European Conference on Computer Vision (ECCV) Workshop.
Automatically generating natural language descriptions from an image is a challenging problem in artificial intelligence that requires a good understanding of the visual and textual signals and the correlations between them. The state-of-the-art methods in image captioning struggles to approach human level performance, especially when data is limited. In this paper, we propose to improve the performance of the state-of-the-art image captioning models by incorporating two sources of prior knowledge: (i) a conditional latent topic attention, that uses a set of latent variables (topics) as an anchor to generate highly probable words and, (ii) a regularization technique that exploits the inductive biases in syntactic and semantic structure of captions and improves the generalization of image captioning models. Our experiments validate that our method produces more human interpretable captions and also leads to significant improvements on the MSCOCO dataset in both the full and low data regimes.@inproceedings{Goel20, title = {Injecting Prior Knowledge into Image Captioning}, author = {Goel, Arushi and Fernando, Basura and Nguyen, Thanh-Son and Bilen, Hakan}, booktitle = {European Conference on Computer Vision (ECCV) Workshop}, year = {2020} } -
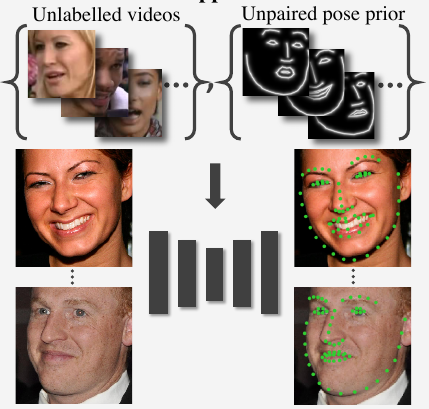
Jakab, T., Gupta, A., Bilen, H., & Vedaldi, A. (2020). Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
We propose a new method for recognizing the pose of objects from a single image that for learning uses only unlabelled videos and a weak empirical prior on the object poses. Video frames differ primarily in the pose of the objects they contain, so our method distils the pose information by analyzing the differences between frames. The distillation uses a new dual representation of the geometry of objects as a set of 2D keypoints, and as a pictorial representation, i.e. a skeleton image. This has three benefits: (1) it provides a tight ‘geometric bottleneck’ which disentangles pose from appearance, (2) it can leverage powerful image-to-image translation networks to map between photometry and geometry, and (3) it allows to incorporate empirical pose priors in the learning process. The pose priors are obtained from unpaired data, such as from a different dataset or modality such as mocap, such that no annotated image is ever used in learning the pose recognition network. In standard benchmarks for pose recognition for humans and faces, our method achieves state-of-the-art performance among methods that do not require any labelled images for training.@inproceedings{Jakab20, title = {Self-supervised Learning of Interpretable Keypoints from Unlabelled Videos}, author = {Jakab, T. and Gupta, A. and Bilen, H and Vedaldi, A.}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2020}, xcode = {https://github.com/tomasjakab/keypointgan} } -
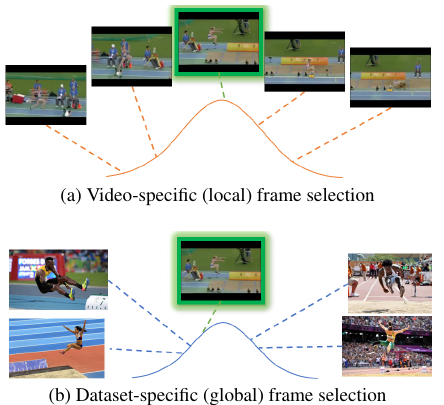
Fernando, B., Tan, C., & Bilen, H. (2020). Weakly Supervised Gaussian Networks for Action Detection. IEEE Winter Conference on Applications of Computer Vision (WACV).
Detecting temporal extents of human actions in videos is a challenging computer vision problem that requires detailed manual supervision including frame-level labels. This expensive annotation process limits deploying action detectors to a limited number of categories. We propose a novel method, called WSGN, that learns to detect actions from weak supervision, using only video-level labels. WSGN learns to exploit both video-specific and datasetwide statistics to predict relevance of each frame to an action category. This strategy leads to significant gains in action detection for two standard benchmarks THUMOS14 and Charades. Our method obtains excellent results compared to state-of-the-art methods that uses similar features and loss functions on THUMOS14 dataset. Similarly, our weakly supervised method is only 0.3% mAP behind a state-of-the-art supervised method on challenging Charades dataset for action localization.@inproceedings{Fernando20, title = {Weakly Supervised Gaussian Networks for Action Detection}, author = {Fernando, B. and Tan, C. and Bilen, H.}, booktitle = {IEEE Winter Conference on Applications of Computer Vision (WACV)}, year = {2020} }
2019
-

Thewlis, J., Albanie, S., Bilen, H., & Vedaldi, A. (2019). Unsupervised Learning of Landmarks by Descriptor Vector Exchange. International Conference on Computer Vision (ICCV).
@inproceedings{Thewlis19, title = {Unsupervised Learning of Landmarks by Descriptor Vector Exchange}, author = {Thewlis, J. and Albanie, S. and Bilen, H. and Vedaldi, A.}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2019}, xcode = {http://www.robots.ox.ac.uk/\~{}vgg/research/DVE/} } -
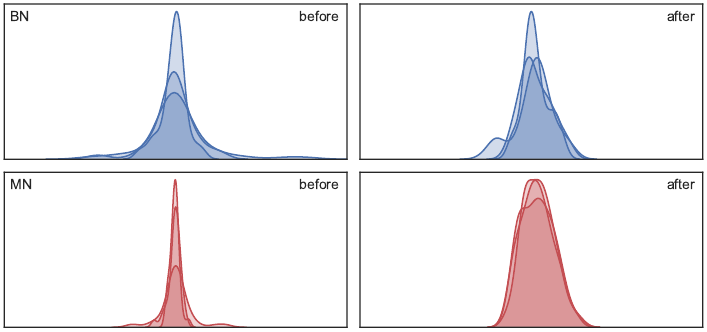
Deecke, L., Murray, I., & Bilen, H. (2019). Mode Normalization. International Conference on Learning Representations (ICLR).
Normalization methods are a central building block in the deep learning toolbox. They accelerate and stabilize training, while decreasing the dependence on manually tuned learning rate schedules. When learning from multi-modal distributions, the effectiveness of batch normalization (BN), arguably the most prominent normalization method, is reduced. As a remedy, we propose a more flexible approach: by extending the normalization to more than a single mean and variance, we detect modes of data on-the-fly, jointly normalizing samples that share common features. We demonstrate that our method outperforms BN and other widely used normalization techniques in several experiments, including single and multi-task datasets.@inproceedings{Deecke19, title = {Mode Normalization}, author = {Deecke, L. and Murray, I. and Bilen, H.}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2019}, xcode = {https://github.com/ldeecke/mn-torch} }