Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps
CVPR 2024 (Oral)
Octave Mariotti, Oisin Mac Aodha, Hakan Bilen
Abstract
Recent progress in self-supervised representation learning has resulted in models that are capable of extracting image features that are not only effective at encoding image-level, but also pixel-level, semantics. These features have been shown to be effective for dense visual semantic correspondence estimation, even outperforming fully-supervised methods. Nevertheless, current self-supervised approaches still fail in the presence of challenging image characteristics such as symmetries and repeated parts. To address these limitations, we propose a new approach for semantic correspondence estimation that supplements discriminative self-supervised features with 3D understanding via a weak geometric spherical prior. Compared to more involved 3D pipelines, our model only requires weak viewpoint information, and the simplicity of our spherical representation enables us to inject informative geometric priors into the model during training. We propose a new evaluation metric that better accounts for repeated part and symmetry-induced mistakes. We present results on the challenging SPair-71k dataset, where we show that our approach demonstrates is capable of distinguishing between symmetric views and repeated parts across many object categories, and also demonstrate that we can generalize to unseen classes on the AwA dataset.
Symmetry-induced confusion
Despite their impressive performances on semantic correspondence benchmarks, recent self-supervised models produce features that are particularly susceptible to confusion between different side of symmetric objects and repeated parts. In essence, they are good at separating the different object parts within an image, but not so much at separating similar ones, and never lear to separate those that do not co-occur in the same image.
Figure 1. PCA of DINOv2 and Stable Diffusion feature maps with corresponding inputs. While features are very consistent across instances, the two opposite sides also produce flipped features.
Architecture and losses
To remedy this, we propose to propose to learn to maps these features to a sphere, acting as a representation of the object surface. A single sphere is learned per category, enforcing cross-instance correspondences
Figure 2. Overview of the architecture.
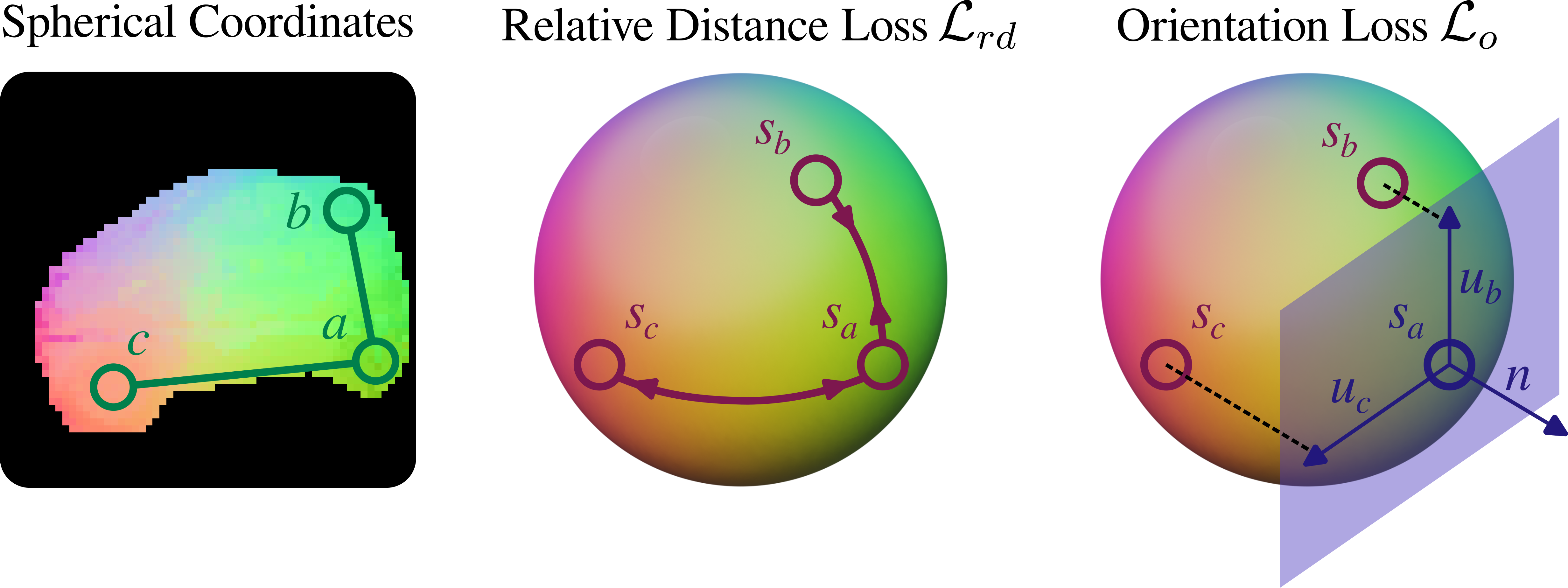
To ensure separation between the different repeated parts and sides, we inject 3D consistentcy losses in the for of a relative distance loss, relative orientation loss, and viewpoint guidance loss.
Figure 3. Overview of the losses.
Keypoint Average Precision
A reason why SSL backbones still perform well even though they make many symmetry-induced mistakes is because the common PCK (Percentage of Correct Keypoint) metric is completely agnostic to such issues. PCK is only evaluated on pairs of keypoint that cooccur in both the source and target image - in this sense, it is a recall-based metric. Because of this, models that predict high similarity between keypoints on the left side and the right side of a car are not penalized.
To resolve such cases, we introduce a new metric, Keypoint Average Precision (KAP). It is designed to be sensitive to such cases by considering all keypoints in the source image, even if they do not appear in the target. If that is the case, a high similarity between the source keypoint and any point in the target would penalise the score.
Figure 4. Illustration of KAP.
Qualitative results
As seen on the visualization, the spherical mapper can disambiguate the repeated parts and different sides of symmetric objects.
Figure 5. PCA of feature maps for multiple SSL backbones, along with spherical maps. Note that in the case of spherical maps, no PCA is needed as the output is already a 3D space.
Related works
A Tale of two Features showcased the effectiveness of DINOv2 and Stable Diffusion features for semantic correspondence. The followup Telling Left from Right identifies similar symmetry-related issues and proposes new supervised losses to fix them
ASIC proposes to align DINO features on a flat 2D atlas rather than a sphere
Dense Equivariant Image Labelling also learns to map objects surfaces to a sphere in an unsupervised way, but does so using image augmentation only and therefore lacks 3D awareness
Citation
If you found our work interesting please cite:
@inproceedings{Mariotti24,
title={Improving Semantic Correspondence with Viewpoint-Guided Spherical Maps},
author={Mariotti, Octave and Mac Aodha, Oisin and Bilen, Hakan},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}