Learning Multiple Dense Prediction Tasks from Partially Annotated Data
CVPR 2022
Abstract
Multi-task Partially-supervised Learning (MTPSL)
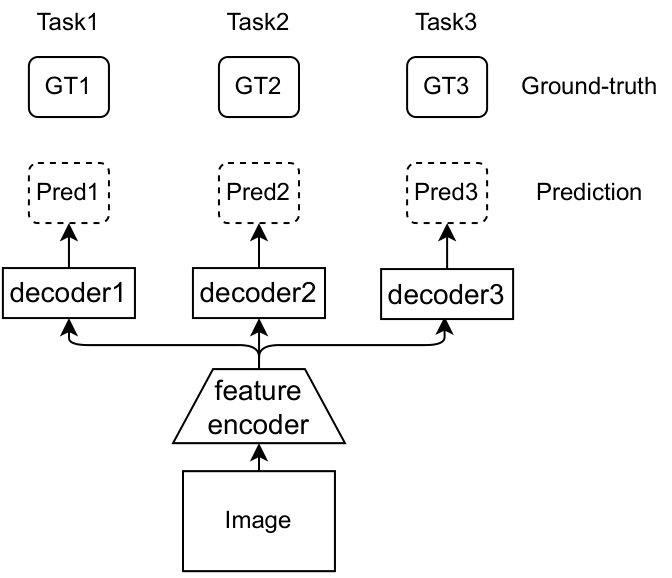
Multi-task Learning (MTL) [1][2][3][4] aims to perform multiple tasks within a single network. However, existing MTL methods require all training images to be labelled for all tasks to learn the MTL model from them (Fig. 1).
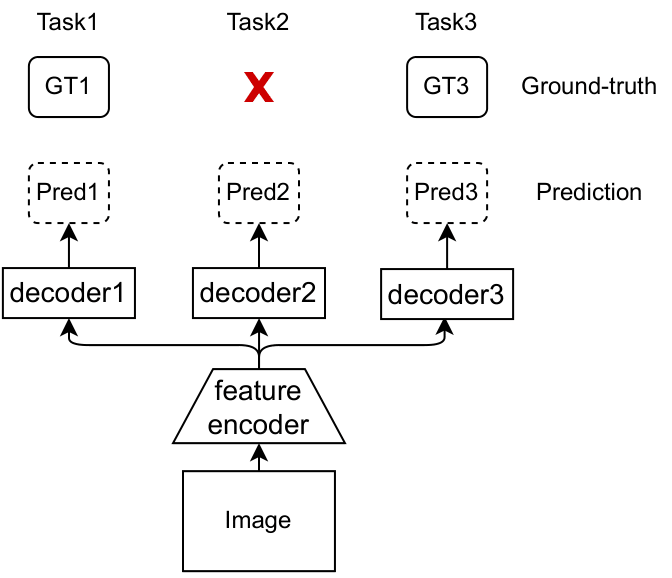
However, obtaining all the labels for each image requires very accurate synchronization between the sensors as collecting the dataset typically involves using multiple sensors to collect annotations for multiple tasks. So it is more common and realistic that the collected dataset is partially annotated. In other words, not all task labels are available in each training image (e.g. in Fig. 2, the image does not have label for task 2). To this end, we propose a more realistic and general setting for MTL, called multi-task partially-supervised learning, or MTPSL, and an architecture-agnostic algorithm for MTPSL.
Learning MTL Model from Partially Annotated Data
Supervised Learning
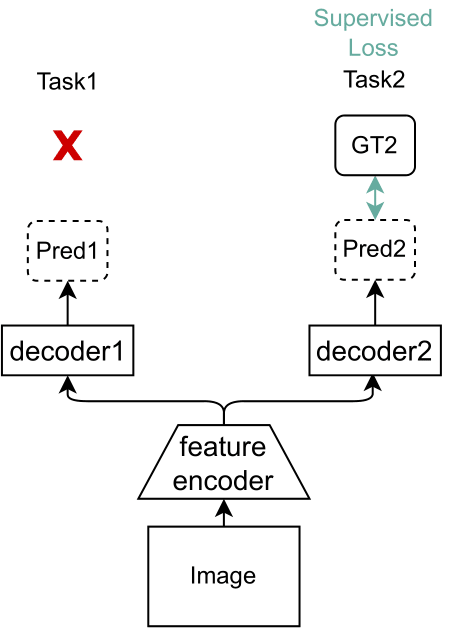
A simple strategy (Supervised Learning) is to apply supervised loss on labelled tasks (Fig. 3). This learns MTL on all images but it cannot extract the task-specific information from the images for the unlabelled tasks.
Semi-supervised Learning
Alternatively, One can extend the Supervised Learning baseline by penalizing the inconsistent predictions of images over multiple perturbations for the unlabelled tasks (Semi-supervised Learning in Fig. 4), but it does not guarantee consistency across the related tasks. For example, if we are going to perform depth estimation and semantic segmentation and an area is wall in segmentation, then that area in depth should be flat.
Cross-task Consistency Learning
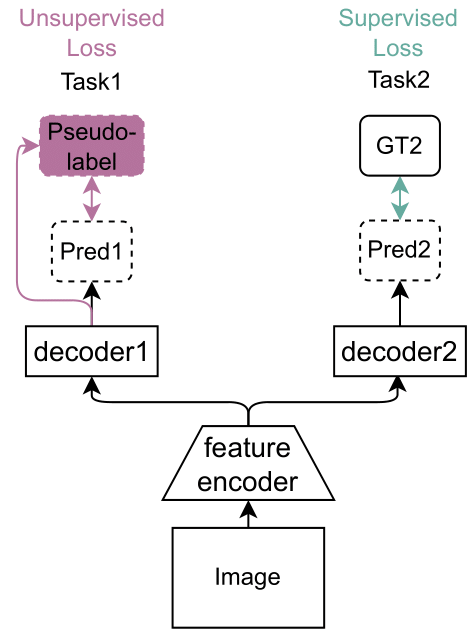
To this end, we propose to leverage cross-task consistency to supervise the learning on unlabelled task (Fig. 5).
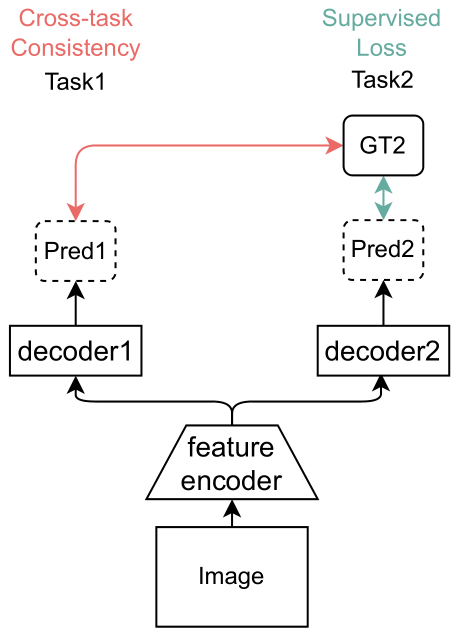
Cross-task Consistency Learning
Direct-Map [5][6]
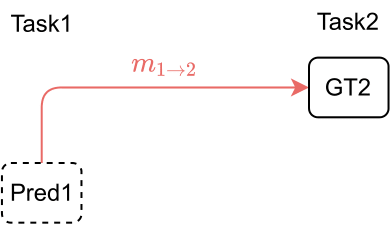
To regularize the cross-task consistency, given the prediction of an unlabelled task and the ground-truth of a labelled task, one can use a mapping function to map prediction of the unlabelled task to labelled task's ground-truth space and align the mapped output with the groundtruth (Fig. 6). However, this direct-map strategy requires analytical derivation from task 1 to task 2 and it assumes task 2 can be recovered from task1.
Joint Space Mapping (Ours)
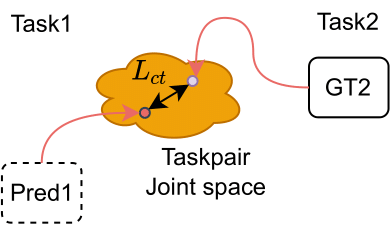
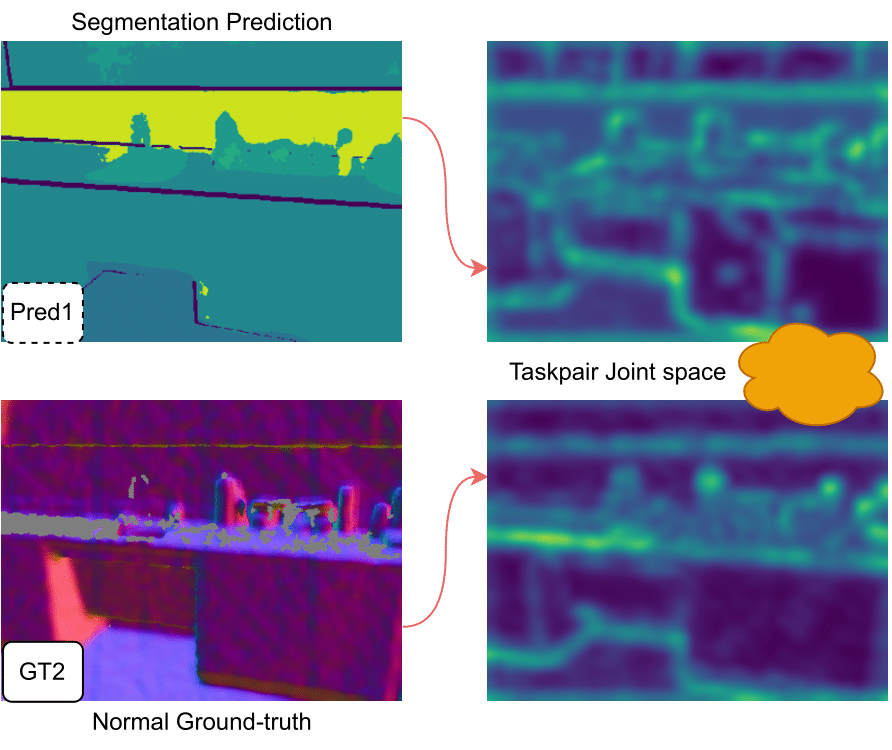
Instead of direct mapping, we propose to map both unlabelled task prediction and labelled task’s ground-truth to a taskpair joint space and regularize the cross-task consistency in the joint space (Fig. 7). This works for any related task pairs and learns only common patterns between task pairs, but naively modelling pairwise relations can be expensive and can result in trivial solutions.
Regularized Conditional Cross-task Joint Space Mapping
To learn the joint space mapping, one can use separate mapping functions for mapping prediction and labels into the joint space. However, the number of taskpair mapping functions grows exponentially with the number of tasks. To address the problem, we propose to use a shared mapping conditioned on the taskpair information (Fig. 8). As shown in Fig. 8, the taskpair information is '\((1 \rightarrow 1,2)\)'.
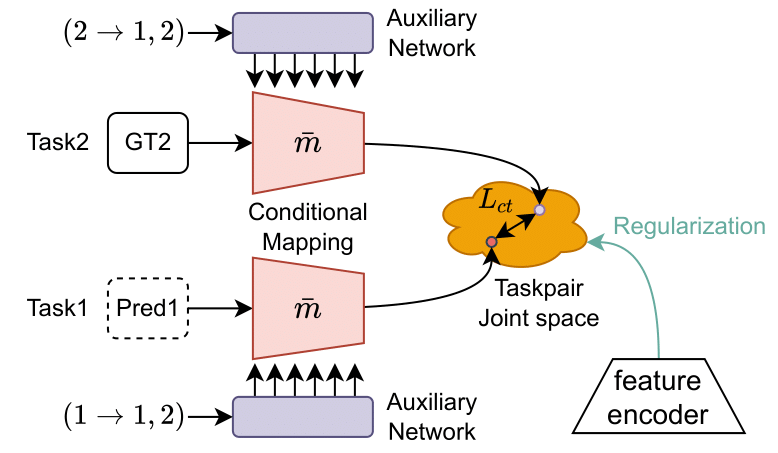
However, the learning of the mappings can lead to trivial solution, for example, the outputs of mappings can be all zeros and the cross-task consistency loss would be zero. To prevent this, we propose to regularize the learning of mappings by aligning the outputs of mappings with a feature from the MTL model's feature encoder. This encourages the mapping to retain high-level information about the input image.
Results
Results on NYU-v2
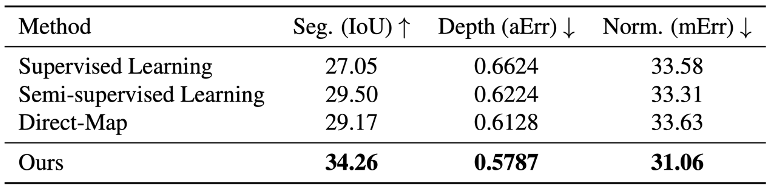
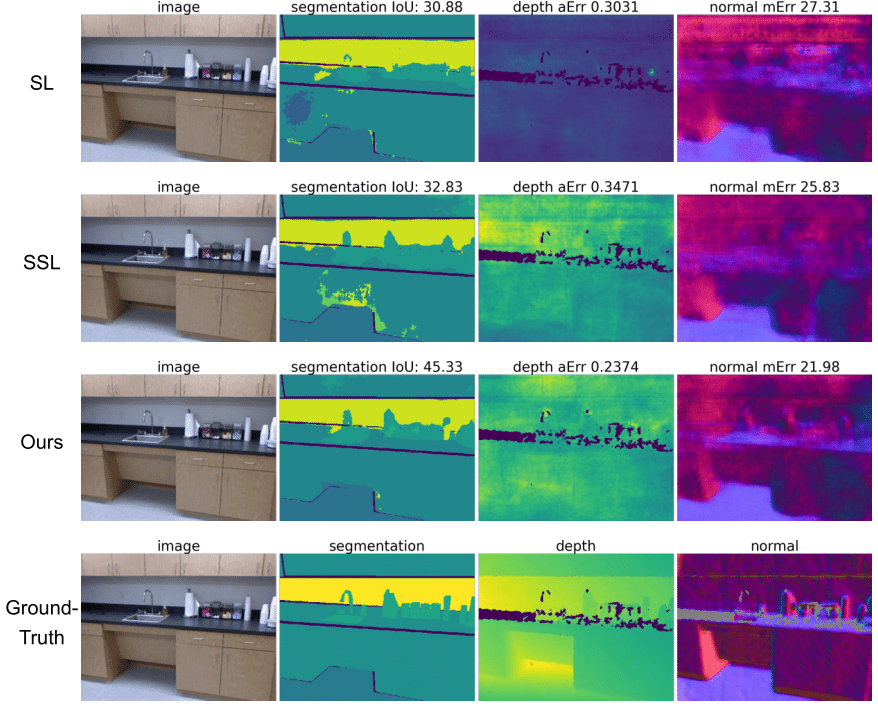
Here, we show results on NYU-v2 which contains indoor images for three tasks: semantic segmentation, depth estimation and surface normal estimation. Table 1 depicts comparisons between Supervised Learning, Semi-supervised Learning and our method under the MTPSL setting where we randomly select and keep labels for 1 or 2 tasks in each image.
Qualitative results on NYU-v2
We also visualize the joint space feature map of the segmentation prediction and surface normal groundtruth at the right column in Fig. 9. The common information is around object boundaries which in turn enables the model to produce more accurate predictions for both tasks (Fig. 10).
Reference
[1] Rich Caruana; Multitask Learning; Machine learning 1997.
[2] Sebastian Ruder; An overview of multi-task learning in deep neural networks; arXiv 2017.
[3] Simon Vandenhende, Stamatios Georgoulis, Wouter Van Gansbeke, Marc Proesmans, Dengxin Dai, and Luc Van Gool; Multi-task learning for dense prediction tasks: A survey; PAMI 2021.
[4] Yu Zhang, Qiang Yang; A survey on multi-task learning; KDE 2021.
[5] Amir R. Zamir, Alexander Sax, Nikhil Cheerla, Rohan Suri, Zhangjie Cao, Jitendra Malik, Leonidas Guibas; Robust learning through cross-task consistency; CVPR 2020.
[6] Yao Lu, Soren Pirk, Jan Dlabal, Anthony Brohan, Ankita Pasad, Zhao Chen, Vincent Casser, Anelia Angelova, Ariel Gordon; Taskology: Utilizing task relations at scale; CVPR 2021.
[7] NathanSilberman, DerekHoiem, PushmeetKohli, Rob Fergus; Indoor segmentation and support inference from rgbd images; ECCV 2012.
[8] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele; The cityscapes dataset for semantic urban scene understanding; CVPR 2016.
[9] Xianjie Chen, Roozbeh Mottaghi, Xiaobai Liu,Sanja Fidler, Raquel Urtasun, Alan Yuille; Detect what you can: Detecting and representing objects using holistic models and body parts; CVPR 2014.