Switchboard in NXT
Data Structure
| HOME |
| OVERVIEW |
| DATA STRUCTURE |
| ANNOTATIONS |
| DATA SUMMARY |
| GETTING STARTED |
| DOWNLOAD |
| PUBLICATIONS |
| LINKS |
| CONTACT US |
The translation of
the multiple layers of annotation of Switchboard into Nite XML
format
allows us to describe the relationships between these layers of
annotation as part of the data structure itself. NXT
tools can then be
used to search over the corpus to extract text with varied discourse,
syntactic, prosodic and phonetic features. Here we briefly describe how
the corpus data is structured in NXT. See the NXT
documentation for
more details, and here for
a brief guide to using NXT tools to search the corpus and the XML
coding itself. Before beginning, it is important for users to be aware of the relationship between the two versions of the transcript
used in the corpus.
This effort has been reasonably successful. However, it is not possible to integrate the two transcripts completely while preserving the accuracy of all the annotations attached to them. For example, if the correction of a mis-transcribed word changes its part-of-speech, this evidently affects the syntactic structure above it. Further, in some cases, such as contractions, the same word is represented as one element in one transcript, and two in the other, e.g. doesn't below. Therefore, it was decided to maintain the two transcripts separately in the corpus, and represent the relationship between them in the data structure, as follows:
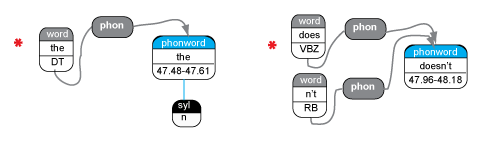
The Penn Treebank
transcript is contained in the 'terminals' codings, i.e. primarily
'word' elements (see explanation below). The MS-State
transcript is contained in the 'phonwords' codings, i.e. primarily
'phonword' elements. 'word' elements have a 'phon' pointer
to the
'phonword' element that they get their timing from. Where there is a
one-to-one mapping between the representation of the same word in each
transcript, e.g. the,
there is simply one 'word' element pointing at the equivalent
'phonword' element. However, where the representation of the same word
in the two transcripts is different, e.g. doesn't, this mapping may be many-to-one or one-to-many, as shown above. Users need to make careful note of this when constructing queries involving words. In the
corpus structure diagram below, elements shown above the 'word' level
are attached to 'words' (nts, markables, etc.). Elements below 'word's
are in fact attached to 'phonword's (syllables, accents, etc.). Links shown in the structure below
with a red star between these elements and 'word's are actually
shorthand: there is a direct relationship between these elements and
'phonwords', and a pointer
between 'word's and 'phonword's. This needs to be described in the query syntax,
e.g. if you want both part-of-speech and syllable information for the
structures above, the query would be (see further on the Getting Started page):
($w word) ($pw phonword) ($s syllable): ($w >"phon" $pw) && ($pw ^ $s)
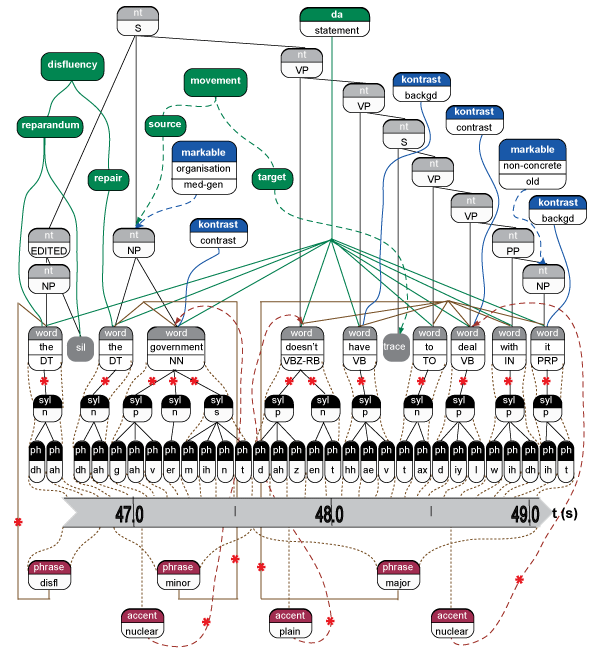
This diagram shows some of the layers of annotation attached to a small portion of speech from a Switchboard conversation (see here for a full summary). We can use this to illustrate how data is represented in NXT:
Two Versions of the Transcript
At the time the project was started, there were two major transcripts of the Switchboard corpus: the original Switchboard/Penn Treebank release, which did not have word timing information; and the corrected MS-State transcript, which included time alignments at the word level. The Penn Treebank transcript already had substantial levels of annotation attached to it, while the MS-State version was obviously necessary to produce phonetic and prosodic annotation. A substantial part of the effort in this project was therefore spent in aligning the two transcripts.This effort has been reasonably successful. However, it is not possible to integrate the two transcripts completely while preserving the accuracy of all the annotations attached to them. For example, if the correction of a mis-transcribed word changes its part-of-speech, this evidently affects the syntactic structure above it. Further, in some cases, such as contractions, the same word is represented as one element in one transcript, and two in the other, e.g. doesn't below. Therefore, it was decided to maintain the two transcripts separately in the corpus, and represent the relationship between them in the data structure, as follows:
($w word) ($pw phonword) ($s syllable): ($w >"phon" $pw) && ($pw ^ $s)
Overall Structure
This diagram shows some of the layers of annotation attached to a small portion of speech from a Switchboard conversation (see here for a full summary). We can use this to illustrate how data is represented in NXT:
- NXT models data as a set of observations, in this case Switchboard conversations. These are associated with one or more signals, here the stereo audio signal (the grey tape).
- Annotations are represented in codings files, one for each type of annotation, e.g. terminals, syntax or kontrast.
- Within each set of codings files, different types of elements are allowed (shown by white writing on filled coloured boxes). For example, above we can see the terminals coding (dark grey) include 'word', 'sil' and 'trace' elements, whereas the phrases codings contain only 'phrase' elements (dark red).
- Each element has optional attributes, whose values give information about that element. These include timing information (nite:start, nite:end), which relates the element to the signal (dotted lines). Above we can see the values of particular attributes for some elements, e.g. the values of the 'cat' (syntactic category) attribute for 'nt' (non-terminal) elements include 'NP', 'VP' and 'S'. Elements can also have textual content, e.g. 'ph' (phone) elements have textual content dh, er, v, etc.
- Elements are related to one another in two ways: Parent-child relationships imply that the children are contained within the parent (solid lines). For example, here 'syl' (syllable) elements are parents of 'ph's; and 'nt' elements are parents of other 'nt' elements and 'word's. Pointer relationships just imply some sort of connection between elements (dashed lines with arrows). For example, here 'accent's are "associated" with 'word's, so they point at them. Pointer relationships can be named, e.g. there are two types of pointer from a 'movement', to the 'source' and the 'target'.