Switchboard in NXT
Getting Started
| HOME |
| OVERVIEW |
| DATA STRUCTURE |
| ANNOTATIONS |
| DATA SUMMARY |
| GETTING STARTED |
| DOWNLOAD |
| PUBLICATIONS |
| LINKS |
| CONTACT US |
Running a GUI
In the top level of the Switchboard NXT-format data download, there are two version of a script that can be used to run the graphical user interfaces: switchboard-guis.sh is for Linux or Mac OSX, and switchboard-guis.bat is for Windows. Before you run the scripts, you first have to edit them to tell them where you have put NXT. Open the script you want to use in a text editor; the instructions are near the top under "Configuration". Once you've saved your changes, you can run the script by double-clicking on it (Windows) or by invoking in a terminal window (Mac/Linux) like this: sh switchboard-guis.sh. This will pop up a window with a list of tools in it. As a good first test, try the one labelled SwitchboardKontrast by selecting it and pressing "Run". You will then get a menu of dialogue names; choose "sw2012" (since this dialogue has existing kontrast coding). You should get a window that looks like this: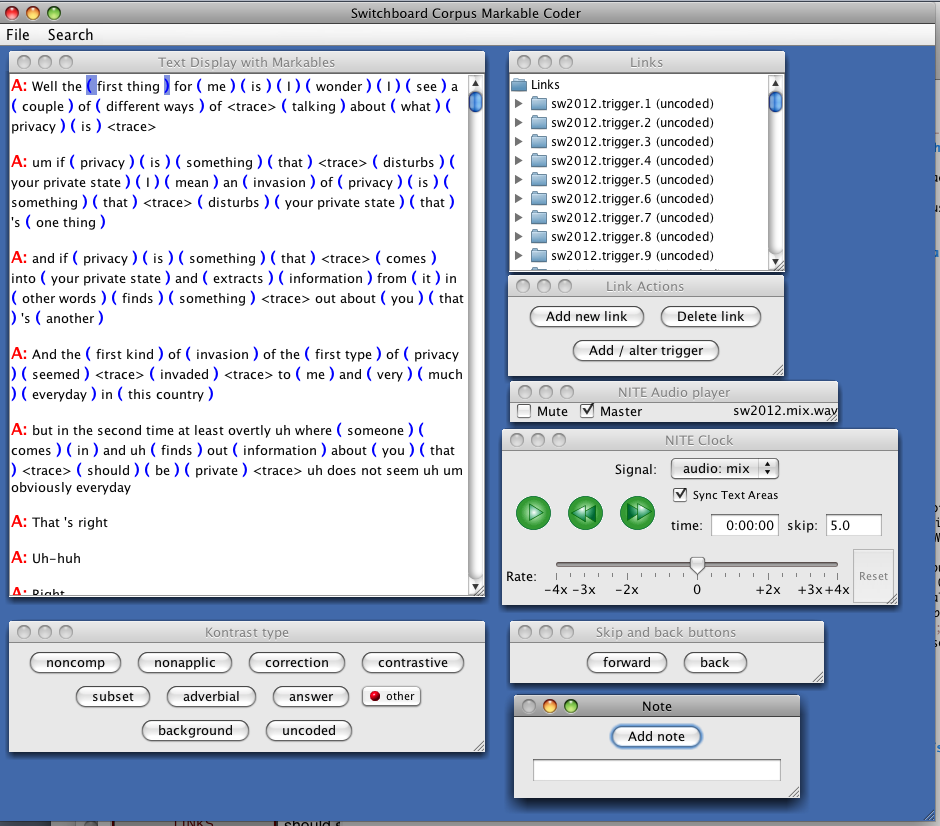
This tool was developed to enable coders to annotate kontrast, but it gives some sense of the corpus in a tailored visual display; the other tools give other kinds of views. If you choose Search... from the Search menu in the top left corner, the following window should open:
In this window, you can type in queries, i.e. a description of the properties of the data you want to extract from the corpus. For instance, if you wanted to see all words that are both children of an NP and old, you would type the following and click Search:
($np nt) ($m markable) ($w word): ($np@cat=="NP") && ($m@status=="old") && ($np ^ $w) && ($m >"at" $np)
The results will be shown in the Results tab. If you click on each match, you will see that each query result is highlighted in the main window.
The query above also shows us the basic elements of the NXT query language, which directly reflects the NXT data structure. On the left, a number of binding variables, with an optional element type (e.g. markable, word) are declared. This is followed by a colon (:). On the right, the required properties of these variables, are listed. For instance, we declare that the value of the cat attribute for the $np variable must be "NP" (note you can also use regular expressions here). We can also query the relationships between variables. Links between elements in a parent-child relationship are specified using the dominance operator (^). Pointer relationships are specified using the arrow operator (>), which is optionally named (e.g. "at"). Users should refer to the data summary for a list of the attributes and relationships for each type of element, and to the NXT documentation for more details about the query language.
As discussed in the description of the data structure, there is a slight complication in the NXT Switchboard corpus, in that there are two versions of the transcript, each with a different set of annotations attached. In the XML representation, words in the Penn Treebank transcript point at their equivalents in the MS-State transcript. Users need to describe this when constructing queries involving both transcripts. For instance, if you wanted to extract all verbs with a nuclear accent, the query would look like this:
($w word) ($pw phonword) ($a accent): ($w@pos ~ /V*/) && ($a@type=="nuclear") && ($w > $pw) && ($a > $pw)
That is, you need a separate variable for the word in each of the two transcripts ($w and $pw), as well as representing the relationship between them ($w > $pw). Users then need to be careful to query the attributes and relationships they are interested in in relation to the right sort of word, e.g. here the part-of-speech information (pos) is an attribute of word elements, while accent elements point at phonword elements.
Command Line Utilities
Once you have a feel for the query language, NXT provides a number of command line utilies which allow you to search over the whole corpus, and output the query results in different ways, depending on your needs. We recommend developing and testing the query syntax on one conversation using one of the graphical user interfaces first, as it easier to see whether the results match what you expect.
To run NXT utilities at the command line, you first need to set up your CLASSPATH environment variable so that java can find NXT. You can find instructions for this by searching the NXT documentation for the word "CLASSPATH". The available NXT tools are fully described in the NXT documentation. As an example, the tool SearchAndFilter allows you to query the data, and then output attributes of the variables queried in tab delimited format:
java SearchAndFilter -corpus swbd-metadata.xml -observation sw2145 -query '($w word) ($pw phonword) ($a accent): ($w@pos ~ /V*/) && ($a@type=="nuclear") && ($w > $pw) && ($a > $pw)' -filter '$w@orth' '$w@nite:start' '$w@nite:end' '$a@nite:start'
The command takes several arguments (most of which are common to all NXT tools). -corpus tells the system the location of the metadata file, which describes the structure and location of all files and layers of annotation in the corpus (see further below). There is an optional -observation argument, if you only want to query one conversation. -query gives the query syntax to extract the data you are interested in. Finally, -filter (which only appears in SearchAndFilter) tells the system which attributes of the variables in the query you want printed out. For example, taking the query above, this command would print out the word, start and end time of the word, and the time of the accent for each match.
XML Format
Although NXT tools have been developed to make extracting data from the corpus easier, the corpus is released in standard, W3C conformant, XML format. Users familiar with XML are therefore free to use tools they are used to to extract information from the corpus. In order to make this easier, we give a short description of the file-naming system used here.The overall structure of the corpus is described in the metadata file, which is equivalent to a DTD. This describes the coding and signals files in the corpus and their location (in relation to the metadata file). The elements allowed in each type of coding file, the attributes of each element, and the values allowed for each attribute are listed.
There are two types of coding file, agent codings and interaction codings. For the interaction codings there is one file for each type of coding per Switchboard conversation, e.g. sw2020.coreference.xml. This gives the conversation ID (as per the original Switchboard release), and the type of coding. For agent codings, these files are split by speaker, e.g. sw2020.A.syntax.xml and sw2020.B.syntax.xml. This was done where there could be temporal overlap between speakers.
Within each coding file, elements allowed for that type of coding are listed. Each element has a unique nite:id, along with its allowed attributes. Parent-child relationships are shown directly by nesting in the XML, or by a nite:child reference to the child element using its nite:id, e.g.:
<nt nite:start="72.593375" nite:end="73.795875" cat="PP" nite:id="s12_509" wc="3">
<nite:child href="sw2145.A.terminals.xml#id(s12_11)"/>
<nt nite:start="73.153375" nite:end="73.795875" cat="NP" nite:id="s12_510" wc="2">
<nite:child href="sw2145.A.terminals.xml#id(s12_12)"/>
<nite:child href="sw2145.A.terminals.xml#id(s12_13)"/>
</nt>
</nt>
Pointer relationships are shown using a nite:pointer reference to the element pointed at using its nite:id, e.g.:
<accent nite:id="sw2145.A.acc1.aw8" nite:start="1.302278" nite:end="1.302278" strength="full">
<nite:pointer role="at" href="sw2145.A.phonwords.xml#id(ms2A_pw4)"/>
</accent>
For more details refer to the NXT documentation.
TGrep2 Format
The NXT data structure is very flexible, allowing a multi-rooted tree where each node can have many types of parents, unordered with respect to each other (as can be seen in the NXT Switchboard structure). To accomodate this, the NXT query language is very powerful, and therefore not as computationally efficient, as more restrictive query languages. As such, it can prove to be (necessarily) slow when queries get complex. Users who only wish to build queries involving syntactic relationships, or involving very complex syntactic relationships in conjunction with minimal information from other layers of annotation, may wish to use the corpus in tgrep2 format. The tgrep2 query language assumes a strictly hierarchical tree structure, and is therefore much faster than NXT.We have previously prepared a version of the corpus in tgrep2 format that is a translation of the NXT syntax and terminal files, but we have not released it because it is based on a quite old version of the corpus. Changes in the corpus representation over the years means that the scripts for constructing it no longer just work. We do, however, have a pretty good idea of how to fix them and whilst we don't need the format ourselves, it's not a major task. If you wish to have the corpus in tgrep2 format, get in touch and we can explain what would be required.