The HCRC Map Task Corpus is a set of 128 dialogues that has been recorded, transcribed, and annotated for a wide range of behaviours, and has been released for research purposes. It was originally designed to elicit behaviours that answer specific research questions in linguistics. You can read more about the design here. Since the original material was released in 1992, the corpus design has been used not just for linguistics research, but also in teaching and by computational linguists for training machine classifiers.
Since HCRC continues to use the Corpus in our own research, we welcome contact with colleagues engaged in similar projects. For this reason we ask users to notify us at maptask@cogsci.ed.ac.uk as a matter of courtesy of the topic of their intended work with these materials.
Because the Map Task is available in a number of forms, we provide a brief history explaining what these are what they contain. Most people just want the most up-to-date version, which is in the format for the NITE XML Toolkit (see NXT-format XML Annotations (v2.1)). The simplest way to acquire the corpus in that format is from the main download page. To make things easier, the audio and maps are available from the same page.
The Original CD-ROMs
In 1992, the HCRC publicly released the HCRC Map Task Corpus on CD. The 8 CD-ROMs contain recordings of the dialogues and read citation word lists, dialogue transcription, and the materials which subjects used to complete the task, including digitised forms of the maps themselves. The CD-ROMs are in High Sierra (ISO 9660) format with the RockRidge extensions, and are compatible with (inter alia) Unix, MS-DOS and Macintosh operating systems.
On the CDs, the waveform data are provided in "raw" (headerless) files (16-bit samples, 20 kHz sample rate, 2 channels per conversation), and alternative header files are provided for use with software based on either the NIST "SPHERE" header structure or the European "SAM" header structure. Transcriptions are provided for each conversation, marked up with TEI-compliant SGML, in a minimally intrusive and easily separated way. PostScript files of the map images used in the experiments are provided, along with full documentation of the experimental design and data collection protocol, resources for using SGML tools on the transcriptions and other text materials, and an extensive set of source code for performing basic signal processing functions on the waveform data, such as down-sampling, de-multiplexing, channel summation, and D/A conversion for Sun workstations (including playback of segments selected via inspection of transcripts in Emacs).
The CD-ROMs are available for purchase from the Linguistic Data Consortium (LDC) (cost payable in US Dollars) for a charge intended to cover the cost of reproduction and distribution.
This readme file explains some omissions and irregularities in the citation word list audio recordings that are available.
Maps
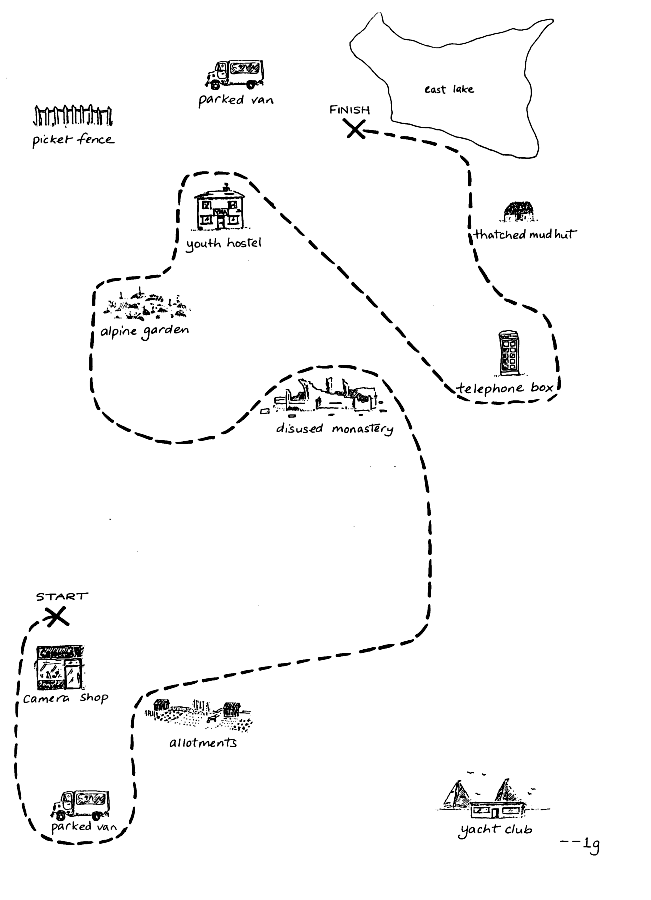
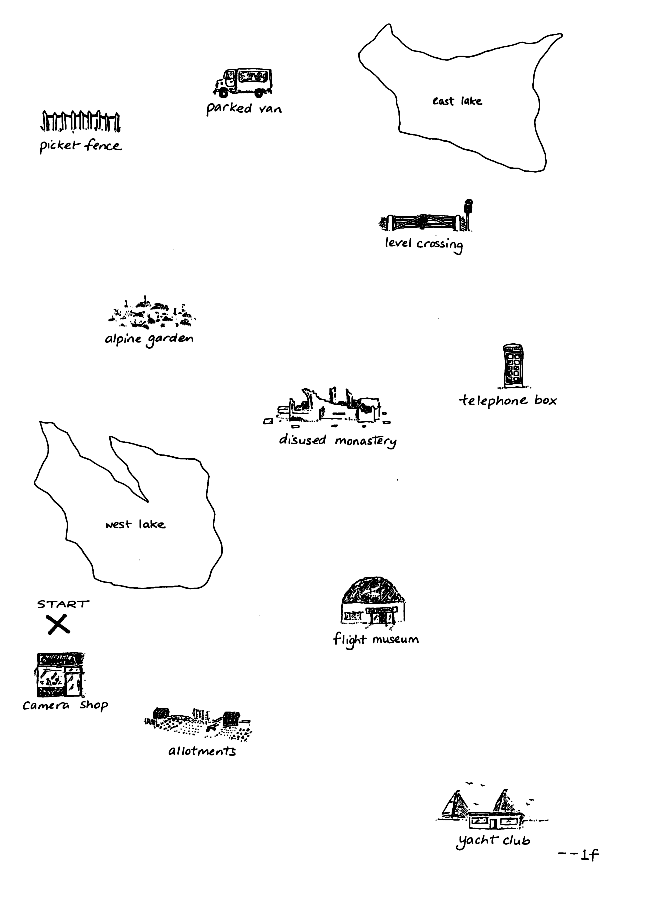
Although the original maps have always been available from the original CD-ROMs, we have often been asked for them separately, especially by those producing corpus replications. They are available from the main download page in three forms: low and high resolution scans of the blank originals, and very low resolution scans of the routes individual route followers drew during the sessions.
Video Recordings

When the corpus was recorded, it included video as well as audio. The videos have been used for research at the Human Communication Research Centre involving the use of gaze, but have never been made freely available for download in order to protect the privacy of the subjects. The recording setup involved two video cameras, one covering one subject, and the other covering the wider space, with the images pasted together into one video frame. Some of the videos have been converted to MPEG format, but many are still as originally recorded on VHS tape.
Original XML Annotations (v1.0)
Soon after its creation, the Map Task Corpus began to be annotated in many different ways, and it became increasingly difficult to look at the relationships among the various behaviours that the annotations described. The HCRC for its own purposes experimented with a number of different data formats and settled on a version of stand-off XML. In 2001, we released the annotations for research purposes. They are still available for download, but we recommend the NXT-format version as a fuller-featured replacement.
On-line demonstration
At around the same time as we created v1.0 of the XML format annotations, we also made the Map Task Interface Demo which runs stylesheets over the XML version of the corpus in real time to produce different views of a dialogue depending on the annotation levels which the user wishes to see. There is a brief but helpful explanation of what the annotations mean.
The demo does not give access to all of the annotations, and it doesn't let you do much of anything with them, but it will give you an idea of what the corpus is like. For actual research, you are better off with the NXT-format XML Annotations (v2.1).NXT-format XML Annotations (v2.1) with Accompanying Audio and Maps
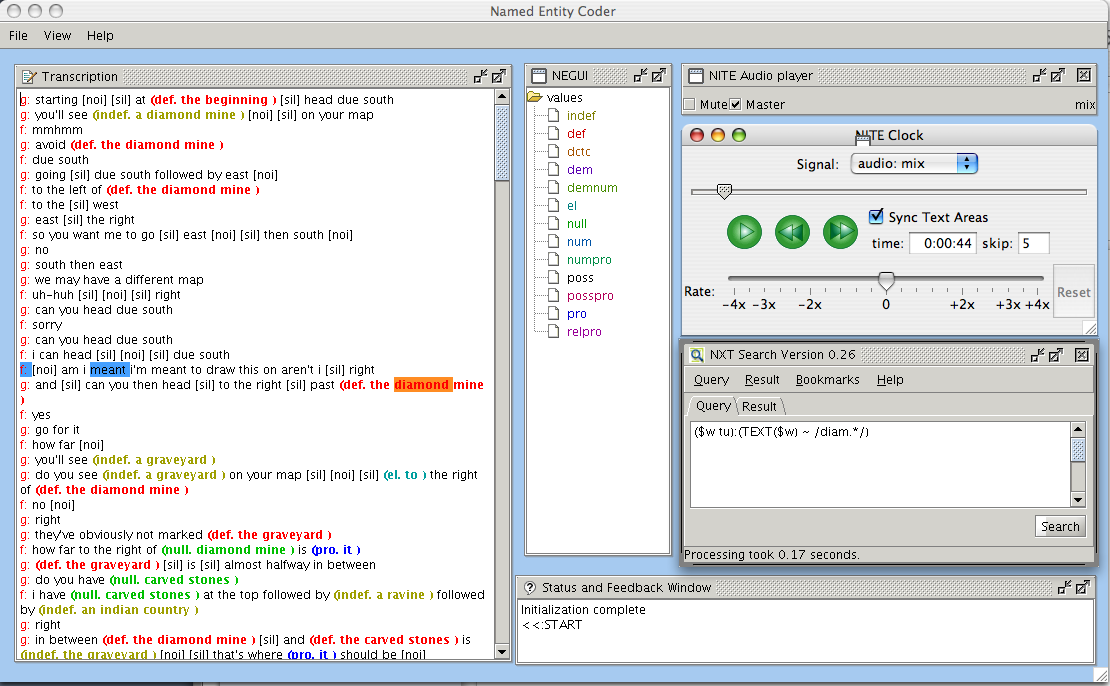
Although the v1.0 XML annotations were well-received, they did not come with any tool support beyond software for XML processing in general. In particular, there was no good way of viewing or editing them in a graphical user interface. For this reason, in 2006-7 we ported the data set to the format required for NITE XML Toolkit. NXT is open source software that was designed with this kind of heavily annotated data set in mind; in fact, the original idea for the toolkit came out of difficulties that HCRC staff had in working with pre-XML versions of the data. The NXT-format version of the data is available from the download page. This includes transcription, annotations and audio, presented as one stereo file in WAV format per dialogue. Users who do not intend to use NXT may still appreciate being able to download audio for the corpus from the web rather than working from the original CDs. Because this format is for the most part a straightforward translation of the v1.0 XML format, it is helpful to read the documentation for the original and the pages associated with the on-line demo that uses the v1.0 format.
Map Task Corpus Replications and Other Uses
The DCIEM Map Task Corpus uses very similar materials to the HCRC Map Task Corpus, but with a different structure designed to test the effects of sleep deprivation under a number of pharmaceutical conditions. The subjects were Canadian army reservists.
The Map Task Corpus has been replicated in whole or in part in a number of languages including Dutch, Italian, Japanese, Swedish, Occitan, and Portuguese. It has also been replicated in part for other forms of English besides the original Glaswegian speakers, including American English, Australian English, and some urban British dialects. The Occitan site has a list of some other language replications. The Map Task has been used to test the effects of many conditions on human communication, including stuttering, computer mediation, textual communication, and the use of avatars.