
The Enhance project
Enhancing the Performance Predictability of Grid Applications with Patterns and Process Algebras
Anne Benoit, Murray Cole, Stephen Gilmore, Jane Hillston and Gagarine Yaikhom
Overview
One of the most promising technical innovations in present-day computing is the invention of Grid technologies which harness the computational and storage power of widely distributed collections of computers. Grid technologies are breaking new ground in e-Science where scientists across the globe can collaborate and share data sets, processing power and specialised scientific instruments to accelerate the pace of scientific development. Grid technologies are also opening new doors in e-Business where small or medium-scale businesses can now have access to supercompting power which was once the province of only the most wealthy banks and multi-nationals. Data and resource sharing schemes such as these are changing the basic ground rules of computing.
All such schemes raise difficult issues of resource allocation and scheduling (roughly speaking, how to decide which computer does what, and when, and how they interact) which are made all the more complex by the inherent unpredictability of resource availability and performance. For example, I may forget to switch on my PC, a supercomputer may be required for a more important task, the internet connections I need may be particularly busy.
The Enhance project aims to simplify the effective programming of such systems by exploiting and synthesizing results from two underlying research programmes. Stochastic process algebras such as PEPA are used to model the behaviour of concurrent systems in which some aspects of behaviour are not precisely predictable. Pattern based programming recognizes that many real applications draw from a range of well known solution paradigms and seeks to make it easy for an application developer to tailor such a paradigm to a specific problem without re-inventing the wheel. The choice of a particular paradigm carries with it considerable information about implied scheduling dependencies. By modelling these with PEPA, and thereby being able to include aspects of uncertainty which are inherent to Grid computing, we believe that we will be able to underpin systems which can make better scheduling and dynamic rescheduling decisions than less sophisticated approaches.
About the project
The vision of Grids as both tools and enabling fabrics for distributed collaborative computation continues to excite applications designers and challenge the Computer Science research community. While some of the issues raised are familiar from previous environments in distributed and parallel computing, many are new.
This project seeks to address the allied problems of programmability, cost predictability and scheduling by augmenting a component based Grid HPC framework with a mechanism for constructing applications as instantiations of pre-defined application patterns. Each pattern will encapsulate the logical behaviour of a familiar pattern of multi-component interaction, at a level of abstraction which simplifies the developer's task, without over constraining the selected implementation. The definition and manipulation of semantic and performance behaviour of components and patterns will be facilitated by the use of a performance oriented process algebra as a modelling tool.
Underpinning an application development process of the form illustrated below, our key insights are:
- that the use of patterns will helpfully constrain the implementation challenge, by providing good knowledge of the overall evolution of an application's interactions;
- correspondingly, that patterns allow both more accurate cost prediction (which in turn informs good scheduling decisions) and lighter weight monitoring (because the pattern based model tells us what the crucial aspects are for each instantiation);
- that cost modelling with a formalised, stochastic performance process algebra and associated tools facilitates capture and manipulation of the remaining uncertain aspects of application behaviour.
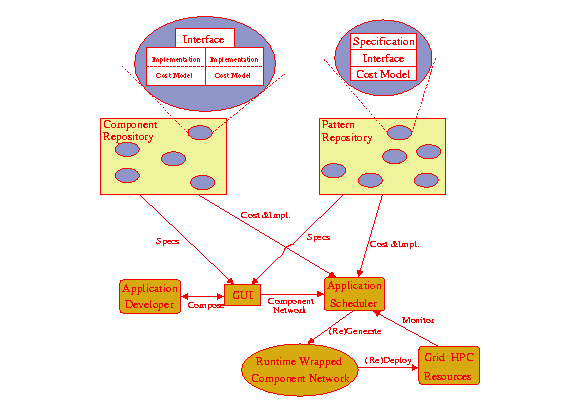
Ultimately, by construction of a prototype and experimentation with a number of case studies, we will demonstrate that this approach allows simple, intuitive construction of applications, and facilitates run-time scheduling and rescheduling with an effectiveness which surpasses that of less constrained methodologies.
(More information about Enhance.)
Case studies
In the Enhance project we have undertaken several case studies to check the practical usefulness of our methods. One of these relates to the on-line scheduling of a numerically-intensive algorithm which uses the Mean Value Analysis algorithm to compute metrics of a queueing network. The algorithm is a pipeline-structured parallel routine implemented using C, MPI and the Edinburgh skeletons library.
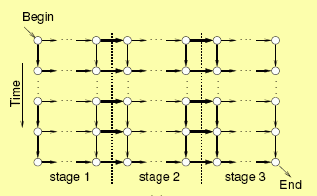
We sample the CPU availability and inter-node TCP communication latency of our Beowulf compute cluster, using the measurement facilities of the Network Weather Service. We then use the measurements so obtained to parameterise our PEPA model of a pipeline-structured parallel application.

We solve the PEPA model using the PEPA Workbench, and derive performance metrics from the result which predict which will be the worst allocation of processes to processors, and which will be the best. By basing our performance predictions on measurements of network latency and compute load we are able to predict ahead-of-run those scheduling decisions which will lead to the shortest run-time and those which lead to the longest runtime. We then run the MVA application on the cluster and measure the run-times.
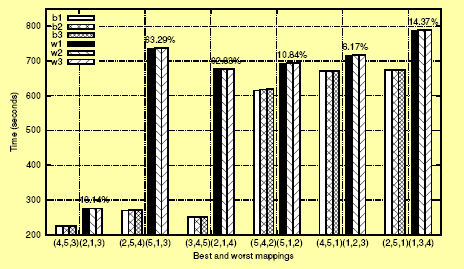
In the present study we did not find a single instance where the performance predictions computed by the PEPA Workbench were misleading: predicted best cases always significantly outperformed predicted worst cases in practice. Strategic use of these methods will reduce the run-times of these parallel codes overall, making better use of heavily-loaded compute clusters.
Members of the Enhance project
- Anne Benoit
- Murray Cole
- Stephen Gilmore
- Horacio Gonzalez-Velez
- Jane Hillston
- Israel Hernandez
- Gagarine Yaikhom
Publications by Year
2004
- Evaluating the Performance of Skeleton-Based High Level Parallel Programs, Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, ICCS 2004: Proceedings of the 4th International Conference on Computational Science, Kraków, Poland, Springer-Verlag Lecture Notes in Computer Science Volume 3038, pp. 289-296, June 6-9, 2004.
- Evaluating the performance of pipeline-structured parallel programs with skeletons and process algebra. Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, To appear in a special issue of Scalable Computing: Practice and Experience SCPE on Practical Aspects of High-level Parallel Programming PAPP 2004, Accepted September 2004.
2005
- Scheduling skeleton-based grid applications using PEPA and NWS. Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, The Computer Journal, Special Focus Issue on Grid Performability, Volume 48, Number 3, pages 369--378, 2005.
- Analyse quantitative de programmes applicatif à base de squelettes algorithmiques, (English version: Quantitative analysis of skeleton-structured applicative programs) Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, Journées Francophones des Langages Applicatifs (JFLA05), Obernai, March 2005.
- Two fundamental concepts in skeletal parallel programming. Anne Benoit and Murray Cole, In proceedings of Practical aspects of High-level Parallel Programming (PAPP 2005), Springer Verlag LNCS 3515, pages 764--771, Atlanta, USA, May 2005.
- Enhancing the effective utilisation of Grid clusters by exploiting on-line performability analysis, Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, CCGrid 2005: Proceedings of the 1st International Workshop on Grid Performability, Cardiff, Wales, IEEE Press, May 2005.
- Flexible Skeletal Programming with eSkel, Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, In J.C. Cunha and P.D. Medeiros (Eds.): Euro-Par 2005, LNCS 3648, pp. 761--770, Lisbon, Portugal, 2005.
- Using eSkel to implement the multiple baseline stereo application, Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, In proceedings of ParCo 2005. Malaga, Spain, September 2005.
- Evaluating the performance of pipeline-structured parallel programs with skeletons and process algebra, Anne Benoit, Murray Cole, Stephen Gilmore and Jane Hillston, Scalable Computing: Practice and Experience, Volume 6, No. 4, pages 1-16, December 2005
2006
- Combining measurement and stochastic modelling to enhance scheduling decisions for a parallel Mean Value Analysis algorithm, Gagarine Yaikhom, Murray Cole, and Stephen Gilmore, Proceedings of 6th International Conference on Computational Science (ICCS 2006), Springer-Verlag LNCS 3992, pages 929--936, May 2006.
Talks and presentations
- Evaluating the performance of skeleton-based grid applications, workshop presentation by Anne Benoit to NeSC Workshop on Grid Performability Modelling and Measurement, Edinburgh, Scotland, March 2004.
- Evaluating the performance of skeleton-based high-level parallel programs, conference presentation by Anne Benoit to ICCS workshop on Practical Aspects of High-level Parallel Programming (ICCS 2004: PAPP 2004), Kraków, Poland, May 2004.
- Why structured parallel programming matters, invited talk by Murray Cole to the Euro-Par conference in Pisa, September 2004.
- Enhancing the performance of Grid Applications with Skeletons and Process Algebras, departmental seminar presentation by Anne Benoit in Pisa, December 2004.
- Analyse quantitative de programmes applicatif à base de squelettes algorithmiques, conference presentation by Anne Benoit to Journées Francophones des Langages Applicatifs (JFLA05), Obernai, March 2005.
- Enhancing the effective utilisation of Grid clusters by exploiting on-line performability analysis, presented by Stephen Gilmore at the CCGrid 2005 workshop on Grid Performability, Cardiff, May 2005.
- Evaluation des performances de programmes parallèles haut niveau à base de squelettes algorithmiques, presentation by Anne Benoit to LACL, Paris 12, May 2005.
- The Righteous and the Wicked: efficient high-level methods for performance analysis, departmental colloquium by Stephen Gilmore at the School of Computing Science, University of Newcastle upon Tyne, June 2005.
Software
- Skeleton programming library with dynamic scheduling support
This library provides a set of interfaces for developing message passing applications with support for dynamic scheduling. The interfaces are based on algorithmic skeletons, and were developed as part of the Enhance project. This library requires an MPI implementation (LAM-MPI was used to test the library). - wflow2pepa (Workflow to PEPA)
The wflow2pepa application program can be used to model performance of workflow systems. The user provides a description file by using a form of hierarchical pattern based language. From this, the application generates the corresponding PEPA performance model automatically.
Funding
The Enhance project was funded by the Engineering and Physical Sciences Research council grant number GR/S21717/01. The project commenced on June 1st 2003 and ended on March 1st 2007.