
The geoparser is implemented in modular fashion, as a sequence of steps arranged in a “pipeline”. The aim is to make it easy to switch different components in if desired, for instance if a local POS tagger is preferred to the one supplied here.
As illustrated in Figure Overview of the geoparser pipeline, there are two stages to the geoparsing process:
- Geotagging
- Georesolution
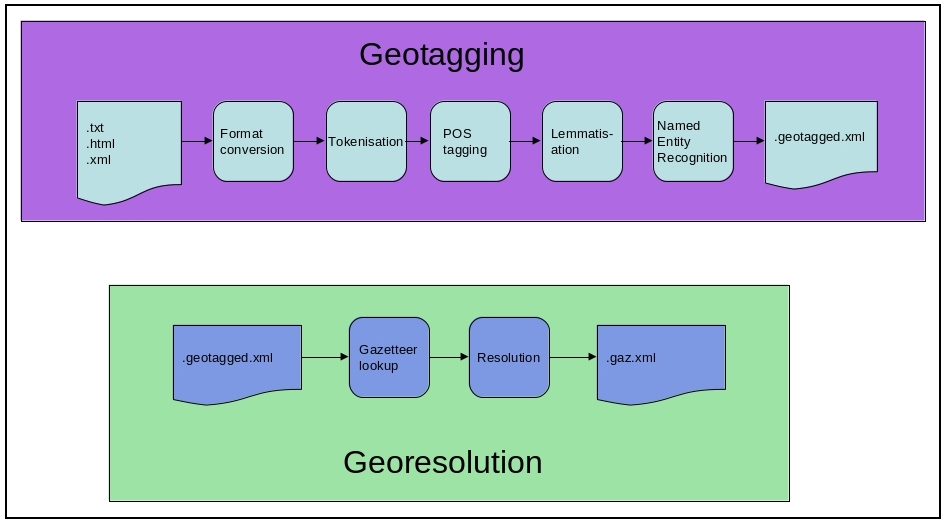
Overview of the geoparser pipeline
The geotagging step process input text to identify and classify named entities within it, specifically placename entities though other classes can also be found - see The nertag Component.
The georesolution step uses a gazetteer (see Gazetteers) to ground placename entities against specific geographic locations mentioned in the gazetteer. Typically there will be multiple candidates - for example, there are any number of places called “Edinburgh” in the world. The georesolver ranks the candidates in order using various contextual clues.