Our approach to data modelling is motivated by the need to have many different kinds of annotations for the same basic language data, for linguistic levels ranging from phonology to pragmatics. There are two reasons why such cross-annotation is prevalent. First, corpora are expensive to collect even without annotating them; projects tend to reuse collected materials where they can. Second, with the advent of statistical methods in language engineering, corpus builders are interested in having the widest possible range of features to train upon. Understanding how the annotations relate is essential to developing better modelling techniques for our systems.
Although how annotations relate to time on signal is important in corpus annotation, it is not the only concern. Some entities that must be modelled are timeless (dictionaries of lexical entries or prosodic tones, universal entities that are targets of referring expressions). Others (sentences, chains of reference) are essentially structures built on top of other annotations (in these cases, the words that make up an orthographic transcription) and may or may not have an implicit timing, but if they do, derive their timings from the annotations on which they are based. Tree structures are common in describing a coherent sets of tags, but where several distinct types of annotation are present on the same material (syntax, discourse structure), the entire set may well not fit into a single tree. This is because different trees can draw on different leaves (gestural units, words) and because even where they share the same leaves, they can draw on them in different and overlapping ways (e.g.,disfluency structure and syntax in relation to words). As well as the data itself being structured, data types may also exhibit structure (for instance, in a typology of gesture that provides more refined distinctions about the meaning of a gesture that can be drawn upon as needed).
The best way to introduce the kind of data NXT can represent is by an example.
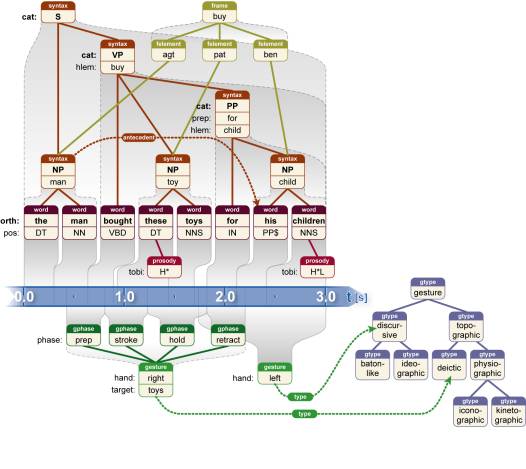
The picture, which is artificially constructed to keep it simple,
contains a spoken sentence that has been coded with fairly
standard linguistic information, shown above the representation
of the timeline, and gestural information, shown below it. The
lowest full layer of linguistic information is an orthographic
transcription consisting of words marked with part-of-speech tags
(in this set, the tag PP$ stands for “personal
pronoun”). Some words have some limited prosodic information
associated with them in the form of pitch accents, designated by
their TOBI codes. Building upon the words is a syntactic
structure — in this formalism, a tree — with a category giving
the type of syntactic constituent (sentence, noun phrase, verb
phrase, and so on) and the lemma, or root form, of the word that
is that constituent’s head. Prepositional phrases, or PPs,
additionally specify the preposition type. The syntactic
constituents are not directly aligned to signal, but they inherit
timing information from the words below them. The very same
syntactic constituents slot into a semantic structure that
describes the meaning of the utterance in terms of a semantic
frame (in this case, a buying event) and the elements that fill
the roles in the frame (the agent, patient, and beneficiary).
The last piece of linguistic information, a link between the
syntactic constituent “the man” and the personal pronoun “his”,
shows that the former is the antecedent of the latter in a
coreference relationship.
Meanwhile, the gesture coding shows two timed gestures and their relationship to a static gesture ontology. In the ontology, one type is below another if the former is a subtype of the latter. The first gesture, with the right hand, is a deictic, or pointing, gesture where the target of the pointing is some toys. This gesture is divided into the usual phases of preparation, stroke, hold, and retraction. The second gesture, made with the left hand, is discursive, but the coder has chosen not to qualify this type further. Gesture types could be represented on the gestures directly in the same way as parts of speech are represented for words. However, linking into an ontology has the advantage of making clear the hierarchical nature of the gesture tag set.
All of these kinds of information are used frequently within their individual research communities. No previous software allows them to be integrated in a way that expresses fully how they are related and makes the relationships easy to access. And yet this integration is exactly what is required in order to understand this communicative act fully. No one really believes that linguistic phenomena are independent; as the example demonstrates, deictic speech can only be decoded using the accompanying gesture. Meanwhile, many linguistic phenomena are correlated. Speaker pauses and hearer backchannel continuers tend to occur at major syntactic boundaries, an argument builds up using rhetorical relations that together span a text, postural shifts often signal a desire to take a speaking turn, and so on. The NITE XML Toolkit supports representing the full temporal and structural relationships among different annotations both as a way of keeping all of the annotations together and to allow these relationships to be explored, since understanding them should help our research.
Although the example shows a particular data structure that necessarily makes choices about for instance, how to represent coreferential relationships and what gestures to include in a taxonomy, NXT deliberately does not prescribe any particular arrangement. Instead, it is designed to be theory-neutral. NXT allows users to define their annotations and how they relate to each other, within constraints imposed by its internal data representation, the NITE Object Model. Notice that in the example, although the overall graph is not a tree, it contains trees as prominent components. The NITE Object Model treats annotations as nodes in a set of intersecting trees. Each node in the model must have at most a single set of children, but might have several parents, defining its placement in different trees. Each tree has an ordering for the nodes that it contains, but there is no order for the set of annotations overall. In addition to the intersecting tree structure, each node can have out-of-tree links, called "pointers", to other nodes. In the NITE Object Model, pointers can introduce cycles into the data structure, but parent-child relationships cannot. This makes it technically possible to represent any graph structure in the model, but at a high processing cost for operations involving pointers.
should NOM come before Data Set Model or after?
The NITE Object Model consists of a general graph structure, and then some properties imposed on top of that graph structure that make using that structure more computationally tractable whilst still expressing the sorts of relationships that are prevalent among annotations.
The NITE Object Model is a graph where the nodes are required to have a simple type and may additionally have attribute-value pairs elaborating on the simple type, timings, children that the node structurally dominates, textual content, pointers relating the node to other nodes, and external pointers relating the node to external data not represented in the NITE Object Model. Any individual node may have either children or textual content, but not both.
TEMP do we want to restrict the NOM by definition so that only one external pointer can be included in any node? This is the de facto restriction in the way external-reference-layers are defined, but the NOM is often less restricted than the layer structure, and it makes sense to me to keep the structure as parallel to pointers as possible (including keeping the arity open).
The simple type is a string.
An attribute is identified by a simple label string and takes a value that conforms to one of three types: a string, a number, or an enumeration. The simple type of the element determines what attributes it can contain. For any element, the simple type plus the attribute-value pairs defined for the element represent its full type.
Timing information can be present, and is represented by reserved start and end attributes containing numbers that represent offsets from the start of the synchronized signals.
The children are represented by an (ordered) list of other nodes.
The textual content is a string. For nodes that have children instead of textual content, some NXT-based tools use an informal convention that the textual content of the node is equivalent to textual content of its descendants, concatenated in order and whitespace-separated.
The pointers are represented by a list of role and filler pairs. A role is a simple label string that has an expected arity, or number of nodes, expected to fill the role: one, or one-or-more. A role is filled by a set of nodes with the expected arity. We sometimes use the term features for these pointers.
The external pointers are also represented by a list of role and filler pairs. A role is again a simple label string with an expected arity of one or one-or-more. The role of an external pointer is filled by a string that specifies a datum in the external reference format, with the details of how the referencing works left to the application program. This can be useful, for instance, in tailored applications that need to cooperate with existing tools that display data in the other format.
The object model also imposes some properties on the parent-child relationships within this general graph structure. Firstly, the parent-child relationships in this graph must be acyclic, so that its transitive closure can be interpreted as a dominance relation. Secondly, there must not be more than one path between any two elements. Because of these constraints, the parent-child graph (which, unlike a tree, allows children to have multiple parents) decomposes into a collection of intersecting tree-like structures, called hierarchies. Each hierarchy has its own structural ordering (similar to an ordered tree), but these orderings must be consistent where hierarchies intersect.
If an element has timing information, the element's start time must be less than or equal to its end time. In addition, if elements in a dominance relation both have timing information, the time interval associated with the ancestor must include that of the descendant. The times of elements need not be consistent with any of the structural orderings. Timing information can thus be used to define an additional partial ordering on the graph, which is not restricted to a single hierarchy.
In the object model, there are no structural or timing constraints imposed on nodes based on the pointers between them. The pointers merely provide additional, arbitrary graph structure over the top of the intersecting hierarchy model.
TEMP We say nodes can have text or children, not both, and that text content of non-leaves is concatenation of descendent's text as informal convention in some tools - is this correct?
Our object model is simply an abstract graph structure with a number of properties enforced on it that govern orderings. However, it can be difficult for data set designers to think of their data in terms this abstract, rather than the more usual concepts such as corpus, signal, and annotation. For this reason, we provide a data set model in these familiar terms that can easily be expressed using our object model and from whose structure the essential properties we require regarding orderings and acyclicity fall out. Data set designers use this level of the model to describe their designs, and by providing metadata that expresses the design formally, make it possible to validate the overall structure of any specific data set against their intended design.
Here we describe the main entities and relationships that occur in our data set model.
Data Set Model Concepts
- Observation
An observation is the data collected for one interaction — one dialogue or small group discussion, for example.
- Corpus
A corpus is a set of observations that have the same basic structure and together are designed to address some research need. For each simple data type, metadata for the corpus determines what attribute-value pairs can be used to refine the type, whether or not elements of that type have timing information and/or children, and what features can be present for them.
- Agent and Interaction
An agent is one interactant in an observation. Agents can be human or artificial. We provide the concept of agent so that signals and annotations can be identified as recording or describing the behaviour of a single agent or of the interacting group as a whole. As an example, individual agents speak, but it takes two of them to have a handshake, and possibly the entire set to perform a quadrille. Any signal or annotation involving more than an individual agent counts as belonging to the interaction even if it involves a subset of the agents present.
- Signal
A signal is the output from one sensor used to record an observation: for example, an audio or video file or blood pressure data. An observation may be recorded using more than one signal, but these are assumed to be synchronized, so that timestamps refer to the same time on all of them. This can be achieved through pre-editing. Individual signals can capture either one agent (for instance, a lapel microphone or a close-up camera) or the interaction among the agents (for instance, a far-field microphone or overhead camera).
- Layer
A layer is a set of nodes that together span an observation in some way, containing all of the annotations for a particular agent or for the interaction as a whole that are either of the same type or drawn from a set of related types. Which data types belong together in a layer is defined by the corpus metadata. For instance, the TEI defines a set of tags for representing words, silences, noises, and a few other phenomena, which together span a text and make up the orthographic transcription. In this treatment, these tags would form a layer in our data set model.
- Time-aligned layer
A time-aligned layer is a layer that contains nodes timed directly against signal.
- Structural layer
A structural layer is a layer where the nodes have children. The children of a structural layer are constrained to be drawn from a single layer, which, in order to allow recursive structures, can be itself. Ordinarily nodes in this layer will inherit timing information from their children if their children are timed, but this inheritance can be blocked.
- Featural layer
A featural layer is a layer where the nodes point to other nodes, but do not contain children or timing information. A featural layer draws together other nodes into clusters that represent phenomena that do not adhere to our timing relationships. For instance, a featural layer might contain annotations that pair deictic gestures with deictic pronouns. Since deictic pronouns and their accompanying gestures can lag each other by arbitrary amounts, there is no sense in which the deictic pair spans from the start of one to the end of the other.
- External reference layer
External reference layers give a mechanism for pointing from an NXT data graph into some data external to NXT that is not in NXT's data format. In an external reference layer, the nodes point both to other NXT nodes and specify a reference to external data. For instance, an external reference layer might contain annotations that pair transcribed words with references in an ontology represented in OWL.
- Coding
A coding is a sequence of one or more layers that describe an observation, all either for the same agent or for the interaction as a whole, where each layer’s children are taken from the next layer in the sequence, ending either in a layer with no children or in a layer whose children are in the top layer of another coding. Codings defined in this way consist of tree structures, and the relations among codings allow the intersecting hierarchies of the NITE Object Model. Since most coherent annotations applied to linguistic data fit into tree structures, for many corpora, the codings will correspond to what can be thought of loosely as types of annotation.
- Corpus Resource
A corpus resource is a sequence of one of more layers that provide reference data to which coding nodes can point. A corpus resource might be used, for instance, to represent the objects in the universe to which references refer, the lexical entries that correspond to spoken word tokens, or an ontology of types for a linguistic phenomena that provides more information than the basic strings given in a node's simple type. The nodes in a corpus resource will not have timing information. For backwards compatibility, NXT corpora may describe individual corpus resources as object sets or ontologies, where object sets are expected to form flat lists and ontologies may have tree structure.
- Code
A code is an individual data item, corresponding to one node in the NITE Object Model. The metadata declaration for codes of a specific type defines the attribute-value pairs that are allowed for that type. If the code relates to other codes using pointers, the declaration specifies by role in which layer the target of the pointer must be found. Further restrictions on the types allowed as children for any given code arise from the layer in which the code is placed.
Together, these definitions preserve the ordering properties that we desire; intuitively, time-aligned and structural layers are ordered, and timings can percolate up structural layers from a time-aligned layer at the base. The layer structure within a coding prohibits cycles.
The structure of any particular data set is declared in these terms in the metadata file for the corpus and imposed by it; for instance, if you validate a corpus against the metadata, any nodes that violate the layering constraints declared in the metadata will be flagged. However, technically speaking, the NITE Object Model itself is perfectly happy to load and work with data that violates the layer model as long as the data graph itself contains no cycles. A number of previous corpora have violated the layering model deliberately in order to avoid what the designers see as too rigid constraints (see Skipping Layers). We don't recommend this because violations can have unintended consequences unless the designers understand how NXT's loading, validation, and serialization work, and may not continue to have the same effects as NXT development continues.
TEMP the AMI ontologies appear to declare both names and filenames - must be wrong?
TEMP do we need a section explaining filenaming for object sets, or are we deprecating them?
NXT corpora are serialized, or saved to disk, into many
different XML files in which the structure of the data graph in the
NITE Object Model is expressed partly using the XML structure of the
individual files and partly using links between files.
NXT is designed to allow data to be divided into namespaces, so that different sites can contribute different annotations, possibly even for the same phenomena, without worrying about naming conflicts. Any code or attribute in a NITE Object Model can have a name that is in a namespace, by using an XML namespace for the XML element or attribute corresponding to the NOM code or attribute. However, see NXT bug 1633983 for a description of a bug in how the query parser handles namespaced data.
The nite: namespace, "http://nite.sourceforge.net/",
is intended for elements and
attributes that have a special meaning for NXT processing, and
is used for them by default. This covers, for instance, the ids
used to realize out-of-file links and the start and end times that
relate data nodes to signal.
Although use of the nite:
namespace makes for a clearer data set design, nothing in the
implementation relies on it; the names of all the elements and
attributes intended for the nite: namespace can be
changed by declaring an alternative in the metadata file, and they
do not have to be in the nite: namespace.
In addition the nite: namespace, corpora that choose
XLink style links (see
Fix this link!
) make use of the
xlink: namespace, http://www.w3.org/1999/xlink.
As for any other XML, NXT files that make use a namespace must declare the
namespace. This includes the metadata file.
One way of doing this is to add the declaration as an attribute
on the document (root) element of the file. For instance,
assuming the default choices of
nite:root for the root element name and nite:id
for identifiers, the declaration for the nite: namespace
might look like this:
<nite:root nite:id="stream1" xmlns:nite="http://nite.sourceforge.net/"> ... </nite:root>
For more information about namespacing, see http://www.w3.org/TR/REC-xml-names/.
The data set model places codes strictly in layers, with
codings made up of layers that draw children from each other in
strict sequence. This is so that within-coding parent-child
relationships can be represented using the structure of the XML
storage file itself. For a single observation,
each coding is stored as a single XML file. The top of each XML tree
is a root element that does not correspond to any
data node, but merely serves as a container for XML elements
that correspond to the nodes in the top layer of the coding being
represented. Then the within-coding children of a node will be
represented as XML children of that element, and so on. Within
a layer, represented as all elements of a particular depth from
the XML file root (or set of depths, in the case of recursive layers),
the structural order of the nodes will be the same as the order
of elements in the XML file.
The structure of a coding file suffices for storing information about
parent-child relationships within a single coding. However, nodes
at the top and bottom layers of a coding may have parent-child relationships
with nodes outside the coding, and any node in the coding may be related
by pointer to nodes that are either inside or outside the coding.
In addition, nodes in external reference layers may be related to
external data stored in files that are not in XML format.
These relationships are expressed in the XML using links.
NXT relies on having two reserved XML element types for representing
links, one for children and one for pointers, including external reference
pointers. The XML element types are, by default, nite:child
and nite:pointer, but they can be changed in the
section of the metadata file that declares reserved elements (see
Reserved Elements and Attributes).
If a NOM node has an out-of-coding child or a pointer, then the XML
element that corresponds to it will represent this relationship by
containing an XML child of the appropriate type.
is it true that external reference pointers use nite:pointer?
Links can be represented in either LTXML1 style or using XLink, but
the choice of link style must be uniform throughout a corpus.
The choice is specified on the <corpus> declaration
within the metadata file (see Top-level corpus description).
NXT can be used to convert a corpus from LTXML1 link style to XLink
style (see ).
NO LINK AVAILABLE
With either link style, the document (XML file) for a reference must be specified without any path information, as if it were a relative URI to the current directory. NXT uses information from the metadata file about where to find files to decode the links. This creates the limitation for external XML processes that use the links that either all the XML files must be in one directory or the external process must do its own path resolution.
Also, with either link style, NXT can read and write ranges in order to cut down storage space. A range can be used to represent a complete sequence of elements drawn in order from the data, and references the sequence by naming the first and last element. Ranges must be well-formed, meaning that they must begin and end with elements from the same layer, and in a recursive layer, from elements at the same level in the layer. To make it easier to use external XML processing that can't handle ranges, NXT can be used to convert a corpus that uses ranges into one that instead references every element individually (see ).NO LINK AVAILABLE
TEMP MORE ABOUT THE SEMANTICS OF RANGES - I'M SURE WE HAD TEXT FOR THIS ONCE BEFORE BUT CAN'T FIND IT. TEMP Are there any constraints on link style and href syntax for external reference links? Can they be in LTXML1 syntax? I suspect the external application is responsible for parsing them, so there are fewer restrictions on what goes in the href attribute. Explain the situation in this section.
In LTXML1 style,
pointers and children will have an (un-name-spaced) href
attribute that specifies the target element.
The following is an example in the LTXML1 style
of an NXT pointer link (using the default
nite:pointer element) that refers to one element.
<nite:pointer role="foo" href="q4nc4.g.timed-units.xml#id('word_1')"/>
The following is an example in the XLink style
of an NXT child link (using the default
nite:child element) that refers to a range of elements.
<nite:child href="q4nc4.g.timed-units.xml#id('word_1')..id('word_5')"/>
When using the XLink style, the target element should conform
to the XLink standard for describing links between resources
http://www.w3.org/TR/xlink/,
and use the
XPointer framework
with the
XPointer xpointer() Scheme
to specify
the URI. NXT only implements a small subset of these
standards, and so requires a very particular link syntax. NXT elements
that express links in this style must include the xlink:type
attribute with the value simple, and specify the
URI in the xlink:href attribute. The xpointer reference
must either refer to a single element within a
document by id or by picking out the range of nodes between two nodes
using the range-to function with the endpoints specified by
id.
The following is an example in the XLink style
of an NXT pointer link (using the default
nite:pointer element) that refers to one element.
<nite:pointer role="foo" xlink:href="o1.words.xml#xpointer(id('w_1'))"
xlink:type="simple"/>
The following is an example in the XLink style
of an NXT child link (using the default
nite:child element) that refers to a range of elements.
<nite:child xlink:href="o1.words.xml#xpointer(id('w_1')/range-to(id('w_5')))"
xlink:type="simple"/>
The actual names used for data and signal files in an NXT corpus depend on the codings and signals defined for it. Rather than containing a complete catalog mapping individual codings and signals to individual files on disk, NXT assumes consistent naming across a corpus. It constructs the names for a file from pieces of information in the data set model (see NITE Data Set Model). Both these pieces of filenames and the paths to directories containing the various kinds of files are specified in the metadata file (see Metadata).
For signal files recording interaction,
the name of the file is found by concatenating the
name of the observation, the name
of the signal, and the extension declared for
the signal, using dots as separators.
For instance, the overhead video, an AVI with extension
avi, for
observation o1 would be stored in file o1.overhead.avi.
For signal files recording individuals, the filename will
additionally have the agent name after the signal
name. For instance, the closeup video, an AVI
with extension avi, for agent A in
observation o1 would be stored in file
o1.A.closeup.avi.
For coding files representing interaction behaviour, the
name of the XML file is found by concatenating the
name of the observation, the
name of the coding, and the extension
xml, using dots as separators. For instance,
the games coding for observation
o1 would be stored in file
o1.games.xml.
For coding files representing agent behaviour, the name of
the XML file will additionally have the agent name
after the observation name. For instance, the
words coding for agent
giver in observation o1
would be stored in file o1.giver.moves.xml.
Because NXT does not prescribe any particular data representation, in
order to load a corpus it requires metadata declaring
what observations, codings, signals, layers, codes,
and so on come with a particular
corpus, and where to find them on disk. This metadata is expressed
in a single file, which is also in XML format.
Each of the example data set extracts comes with
example metadata that can be used as a model.
The DTD and schema for NXT
metadata can be found in the lib/dtd and lib/schema
directories of the NXT
distribution, respectively.
the schema for NXT metadata isn't actually in lib/schema in the NXT distribution, but we say it is.
TEMP Throughout doc, add external-pointer where child and pointer are talked about
TEMP The code tag isn't defined anywhere on this page, I think - and I also think it occurs in more than one place, so presumably it's common and belongs here, under preliminaries.
A number of sections of the metadata (<code>,
<ontology>, <object-set>)
rely on the same basic mechanism for defining attributes. Attributes
can have three different types: string,
meaning free text;
number, where any kind of numeric value is permitted;
or enumerated, where only values listed in the
enclosed value elements are permitted. They are defined
using an <attribute> tag where
the
name attribute gives the name of the attribute and
the value-type attribute, the type. For enumerated attributes,
the attribute declaration must also include the enumerated values
within <value> tags. For instance,
<attribute name="affiliation" value-type="string"/>
defined an attribute named "affiliation" that can have any string value, whereas
<attribute name="gender" value-type="enumerated"> <value>male</value> <value>female</value> </attribute>
defines an attribute named "gender" that can have two possible values, "male" and "female".
Do we want to say anything about the treatment of numerical attributes, since people find that tricky at times - is it just tricky in query (in which case mention it there, or also elsewhere?
The root element of a metadata file is corpus and here's
an example of what it looks like:
<corpus description="Map Task Corpus" id="maptask" links="ltxml1" type="standoff" resource_file="resource.xml"> ... </corpus>
The important attributes of the corpus element are
links and type. The type
attribute should have the value standoff. The previous
use of simple corpora is deprecated. The
links attribute defines the syntax of the standoff links
between the files. It can be one of: ltxml1 or
xpointer. See Links for an explanation
of these two link styles. The resource attribute is
optional: if it is present it specifies a resource file which will be
parsed by NXT (from versions 1.4.1 onwards). Resource files provide a
more flexible way to manage a large NXT corpus, particularly where
many annotators and automatic processes could provide competing
annotations for the same things. See Resource Files for
an explanation of resource files and their format.
There are a number of elements and attributes that are special, or
reserved, in NXT because they do not (or do not just)
hold data but are used in NXT processing, for instance, in order to
identify the start and end times of some timed annotation.
The <reserved-elements> and
<reserved-attributes> sections of the metadata-file
can be used to override their default values. They contain as children
declarations for each element or
attribute separately; each child declaration uses
a different element name (see table), with the name
attribute specifying the name to use for that element or attribute
in the NXT corpus being described.
If the element in the metadata for declaring the name to use for
a particular element or attribute is missing,
then NXT will use the default value for that attribute. The
<reserved-attributes> and
<reserved-attributes> sections of the metadata-file
can be omitted entirely if no declarations are required for the
corpus being described.
Caution
At present, off-line data validation can not fully handle alternative names (see Data validation).
The following table shows each of the reserved attributes along with the name of the element in the metadata file used to declare its name and the default value.
Table 1. Reserved Attributes
| attribute | metadata tag name | default value |
|---|---|---|
| Root / stream element name | stream | nite:root |
| Element identifier | identifier | nite:id |
| Element start time | starttime | nite:start |
| Element end time | endtime | nite:end |
| Agent | agentname | agent |
| Observation | observationname | - |
| Comment | commentname | comment |
| Key Stroke | keystroke | keystroke |
| Resource | resourcename | - |
For instance, a metadata declaration that changes just the names of the id, start, and end time attributes might look like this:
<reserved-attributes> <identifier name="identifier"/> <starttime name="starttime"/> <endtime name="endtime"/> </reserved-attributes>
They are used in NXT processing as follows.
Reserved Attribute Meanings
- Stream
The
streamattribute occurs at the root elements of all XML data files in a corpus apart from ontology files and corpus resources, and gives a unique identifier for the XML document in the file. This attribute does not form part of the data represented in the NITE Object Model, but is required for serialization.- Identifier
Identifiers are required on all elements in an NXT corpus, and are used by NXT to resolve out-of-file links when loading and to maintain the correspondence between the data and the display in GUI tools.
- Start and End Times
Start and end times may appear on time-aligned elements. They give the offset from the beginning of a signal (or set of synchronized signals) in seconds.
- Agent and Observation
These reserved attributes describe not attributes that should occur in the XML data files, but attributes that can be added automatically as data is loaded, for access in the NITE Object Model. Normally, corpora do not explictly represent the name of the observation which an annotation describes, or the name of the agent if it is an annotation for an individual, since this information is represented by where in the set of XML files the data is stored. It would take a great deal of space to stick this information on every data element, but it is useful to have it in the NOM, for instance, so that queries can filter results based on it. The
agentnameandobservationnamedeclarations specify the names to use for these attributes in the NOM. The attributes will be added at load time to every element that doesn't already have an attribute with the same name.- Comment
The
commentattribute gives space to store an arbitrary string with any data element in the corpus. It is typically used for temporary information to do with data management or to represent the cause of uncertainty about an annotation.- Keystroke
Any element can have an associated
keystroke. This is normally used to represent keyboard shortcuts for elements in an ontology, though it can be used for other purposes. The value is simply a string, and what application programs do with the string (if anything) is up to them.- Resource
If the metadata refers to a
resourcefile, this attribute contains the ID of the resource this element is associated with, if any.
keystroke isn't very well thought out - we'd rather have keystrokes on element types, not elements, except for the use in ontologies that you mention. We might consider changing this feature.
The following table shows each of the reserved elements along with the name of the element in the metadata file used to declare its name and the default value.
Table 2. Reserved Elements
| element | metadata tag name | default value |
|---|---|---|
| Pointer | pointername | nite:pointer |
| Child | child | nite:child |
| Stream element | stream | nite:root |
For instance, a metadata declaration covering just the names of pointer elements might look like this:
<reserved-elements> <pointername name="mypointer"/> </reserved-elements>
Changing the reserved element and attribute names from the default affects the representation that NXT expects within the individual XML data files. For instance, suppose we include the following in the metadata file:
<reserved-attributes> <stream name="stream"/> <identifier name="identifier"/> <starttime name="starttime"/> <endtime name="endtime"/> <agentname name="who"/> <observationname name="obs"/> <commentname name="mycomment"/> <keystroke name="mykey"/> </reserved-attributes> <reserved-elements> <pointername name="mypointer"/> <child name="mynamespace:child"/> <stream name="stream"/> </reserved-elements>
Further suppose that the metadata file specifies the use of
ltxml1-style links and goes
on to define a coding file containing one time-aligned layer, with
one code, <word, that declares no further attributes
but can contain syllables as children, and can point to syntactic
constituents using the "antecedent" role.
Then the full XML file representing those words might look like
this:
<stream> <word identifier="word_1" starttime="1.3" endtime="1.5" <mypointer role="antecedent" href="obs1.syntax.xml#ante_2"/> <mynamespace:child href="obs1.syllables.xml#syllable_1"/> </word> ... </stream>
does the CVS stuff work? is it documented? probably in javadoc only? or do we remove this section of the metadata?
Many projects keep their annotations in a CVS repository.
Concurrent version control (see http://www.cvshome.org/)
allows different people to edit the same
document collaboratively, maintaining information about who has done what
to what file when. One NXT contributor is adding functionality
to allow NXT GUIs to work directly from a CVS repository rather than
requiring the annotator to check out data from CVS and then commit changes
as additional steps. The cvsinfo
section of the metadata declares where to
find the CVS repository for these purposes.
It has three attributes, all of which are required:
protocol (one of pserver, ext, local, sspi);
server (the machine name on which the CVS server is hosted);
and module (the top level directory within the CVS repository
where the corpus is found). For instance,
I don't understand which directory should be named in the cvsinfo tag - the one that contains the metadata?
Or does this facility require all data XML files to be in the same directory, and that's the one to use?
<cvsinfo protocol="pserver" server="cvs.inf.ed.ac.uk" module="/disk/cvs/ami"/>
A corpus is a set of observations of language behaviour that
are all of the same basic genre, all of which conform to the same
declared data format. For each corpus, there will be a set number
of agents, or individuals (whether human or artificial) whose behaviour
is being observed. The agents section of the metadata
contains agent declarations for each one.
Each agent declaration must contain a name
attribute, which can be any string that does not contain whitespace.
The agent name will be used to name data and signal files.
If the reserved attribute agentname is declared
(see Reserved Attributes, it
will also be available as an attribute on all agent annotations during
queries.
Agent declarations may also contain a description, which
can be any
string, and is intended to be a short, human-readable description.
Its use is application-specific.
Note that this strategy for naming agents gives uniformity throughout the
corpus; every observation in a corpus will use the same agent names.
That is, the name of an agent expresses its role in the language interaction
being observed. Typical agent names are e.g.
system and user for human-computer dialogue.
For corpora without discernible roles, the labelling is often arbitrary,
using letters to designate individuals, or based
on seating. NXT deliberately places
personal information about the individuals that fill the agent
roles for specific observations in corpus resources, not the metadata,
so that it is accessible from the query language.
Usually, it is obvious how many agents to use for a corpus; e.g., two for dialogue, five for five-person discussion. However, there are a few non-obvious cases.
For corpora of discussions where the size varies but everything else is the same, in order to treat all observations in the same metadata file, you must declare the largest number of agents required by any observation so that one metadata file can be used throughout. In this case, it will be impossible to tell whether an agent speaks no words because they were absent or because they were silent without encoding this information in a corpus resource.
For monologue and written text, it is possible either to declare the corpus as having one agent or as having no agents, treating every annotation as a property of the interaction. The only difference is in how the data files will be named.
Most (but not all) corpora come with either a single signal for each observation, or a set of signals that together record the observation from different angles. In a corpus, the usual aim is to capture all observations with the same recording set-up, resulting in the same set of recordings for all of them. This section of the metadata declares what signals to expect for the observations in the corpus and where they reside on disk. There is an explanation of how filenames are concatenated from parts in Data And Signal File Naming. Filenames are case-sensitive.
At the top level of this section, the
signals declaration uses the path attribute
to specify the initial part of the path to the
directory containing signals. If the path is
relative, it is calculated relative to the location of the metadata file,
not to the directory from which the java application is started. The default
path is the current directory. The signals declaration can
also declare a pathmodifier, which concatenates additional
material to the end of the declared path. For any given observation,
the additional material will
be the result of replacing any instances of the string
observation with the name of that observation.
This allows the signals for a corpus to be broken down into subdirectories
for each observation separately.
Below the signals tag, the metadata is divided into two
sections, agent-signals and
interaction-signals, for agent and interaction signals,
respectively.
Within these sections, each type of signal for a corpus has its
own signal declaration, whch takes an
extension giving the file extension; name,
which is used as part of the filename and should not contain
whitespace; format, which is a
human-readable description of the file format, and type,
which should be audio or video; and again a
pathmodifier, treated in the same way as the pathmodifier
on the signals declaration, and appended to the path
after it. Of these attributes, extension and name
are required, and the rest are optional.
TEMP if we know what signal format and type are for, we should say so. I'm guessing about the restrictions on their values; should check the DTD.
TEMP Removed reference to GVM here since it's incomprehensible along with the other documentation and seems out of place - Note that because there could be several video signals associated with the same observation, any GVM (video overlay markup) needs to know which signal it applies to.
Occasionally the recording setup will not be entirely uniform over a corpus, with individual signals missing or individual observations having one signal or another from the setup, but not both. In these cases, you must over-declare the set of signals as if the corpus were uniform and treat these signals as missing. The main ramification of this in software is that GUIs will give users the choice of playing signals that turn out not to be available unless they check for existence first.
Assume that there is an observation named
o1 and agents g and
f. Then this declaration:
<signals path="../signals/">
<agent-signals>
<signal extension="au" format="mono au"
name="audio" type="audio"/>
</agent-signals>
<interaction-signals>
<signal extension="avi" format="stereo avi"
name="interaction-video" type="video"/>
</interaction-signals>
</signals>
will cause NXT to expect to find the following media files at the following paths:
../signals/o1.g.audio.au |
../signals/o1.f.audio.au |
../signals/o1.interaction-video.avi |
If we were to add the pathmodifier observation
to the signals tag, NXT would look for the signals
at, e.g., ../signals/o1/o1.interaction-video.avi.
If we then also added the pathmodifier video
for the interaction-video, leaving the other signal with no
additional pathmodifier, i.e. declaring as
<signals path="../signals/" pathmodifier="observation">
<agent-signals>
<signal extension="au" format="mono au"
name="audio" type="audio"/>
</agent-signals>
<interaction-signals>
<signal extension="avi" format="stereo avi"
name="interaction-video" type="video"
pathmodifier="video"/>
</interaction-signals>
</signals>
NXT would look for the signals as follows.
../signals/o1/o1.g.audio.au |
../signals/o1/o1.f.audio.au |
../signals/o1/video/o1.interaction-video.avi |
A corpus resource is a set of elements that are globally relevant in some way to an entire corpus. They are not as strictly specified as ontologies or object sets (below). They will probably eventually replace the use of those things. Typically these will be files that come from the original application and can be used almost without alteration. You may specify the exact hierarchical breakdown of such a file, but typically there will just be one recursive layer (pointing to itself) that specifies all the codes permissible. Here is an example where the resource describes participants in a meeting corpus:
<corpus-resources path="."> <corpus-resource-file name="speakers" description="meeting speakers"> <structural-layer name="speaker-layer" recursive-draws-children-from="speaker-layer"> <code name="speaker"> <attribute name="id" value-type="string"/> <attribute name="gender" value-type="enumerated"> <value>male</value> <value>female</value> </attribute> </code> <code name="language"> <attribute name="name" value-type="string"/> <attribute name="region" value-type="string"/> </code> <code name="age" text-content="true"/> </structural-layer> </corpus-resource-file> </corpus-resources>
The path attribute on the corpus resources
element tells NITE where to look for resources for this corpus. A
corpus resource has a name attribute which is unique in the
metadata file. Combined with the name attribute of an individual
resource, we get the filename. The name attribute can also be used to
refer to this object set from a codings layer.
The contents of an individual corpus resource are defined in exactly the same manner as codings layers within codings.
An ontology is a tree of elements that makes use of the parent/child structure to specify specializations of a data type. In the tree, the root is an element naming some simple data type that is used by some annotations. In an ontology, if one type is a child of another, that means that the former is a specialization of the latter. We have defined ontologies to make it simpler to assign a basic type to an annotation in the first instance, later refining the type. Here's an example of an ontology definition:
<ontologies path="../xml/MockCorpus"> <ontology description="gesture ontology" name="gtypes" element-name="gtype" attribute-name="type"/> </ontologies>
The path attribute on the ontologies element
tells NITE where to look for ontologies for this corpus. An ontology
has a name attribute which is unique in the metadata file and
is used so that the ontology can be pointed into (e.g. by a coding
layer - see below). It also has an attribute element-name:
ontologies are a hierarchy elements with a single element name: this
defines the element name. Thirdly, there is an attribute
attribute-name. This names the privileged attribute
on the elements in the ontology: the attributes that define the type
names.
The above definition in the metadata could lead to these contents of the file gtypes.xml - a simple gesture-type hierarchy.
<gtype nite:id="g_1" type="gesture" xmlns:nite="http://nite.sourceforge.net/"> <gtype nite:id="g_2" type="discursive"> <gtype nite:id="g_3" type="baton-like"/> <gtype nite:id="g_4" type="ideographic"/> </gtype> <gtype nite:id="g_5" type="topographic"> <gtype nite:id="g_6" type="deictic"/> <gtype nite:id="g_7" type="physiographic"> <gtype nite:id="g_8" type="iconographic"/> <gtype nite:id="g_9" type="kinetographic"/> </gtype> </gtype> </gtype>
An ontology can use any number of additional, un-privileged
attributes, as long as they are declared in the metadata for
the ontology using an <attribute> tag.
For example, to extend
the ontology above with a new attribute, foo, with possible values
bar and baz, the declaration would be as follows:
<ontology description="gesture ontology" name="gtypes" element-name="gtype" attribute-name="type"> <attribute name="foo" type="enumerated"> <value>bar</value> <value>baz</value> </attribute> </ontology>
An object is an element that represents something in the universe to which an annotation might wish to point. An object might be used, for instance, to represent the referent of a referring expression or the lexical entry corresponding to a word token spoken by one of the agents. When an element is used to represent an object, it will have a data type and may have features, but no timing or children. An object set is a set of objects of the same or related data types. Object sets have no inherent order. Here is a possible definition of an object set - imagine we want to collect a set of things that are referred to in a corpus like telephone numbers and town names:
<object-sets path="/home/jonathan/objects/"> <object-set-file name="real-world-entities" description=""> <code name="telephone-number"> <attribute name="number" value-type="string"/> </code> <code name="town"> <attribute name="name" value-type="string"/> </code> </object-set-file> </object-sets>
The path attribute on the object-sets element
tells NITE where to look for object sets on disk for this
corpus. Combined with the name attribute of an individual
object set we get the filename. The name attribute is also
used to refer to this object set from a coding layer (see below).
The code elements describe the element names that
can appear in the object set, and each of these can have an arbitrary
number of attributes. The above spec describes an object set in file
/home/jonathan/objects/real-world-entities.xml
which could contain:
<nite:root nite:id="root_1"> <town nite:id="town3" name="Durham"/> <telephone-number nite:id="num1" number="0141 651 71023"/> <town nite:id="town4" name="Edinburgh"/> <town nite:id="town1" name="Oslo"/> </nite:root>
where the contents are unordered and can occur any number of times.
Here we define the annotations we can make on the data in the corpus. Annotations are specified using codings and layers, and we start with an example.
<codings path="/home/jonathan/MockCorpus">
<interaction-codings>
<coding-file name="prosody" path="/home/MockCorpus/prosody">
<structural-layer name="prosody-layer"
draws-children-from="words-layer">
<code name="accent">
<attribute name="tobi" value-type="string"/>
</code>
</structural-layer>
</coding-file>
<coding-file name="words">
<time-aligned-layer name="words-layer">
<code name="word" text-content="true">
<attribute name="orth" value-type="string"/>
<attribute name="pos" value-type="enumerated">
<value>CC</value>
<value>CD</value>
<value>DT</value>
</attribute>
<pointer number="1" role="ANTECEDENT"
target="phrase-layer"/>
</code>
</time-aligned-layer>
</coding-file>
</interaction-codings>
</codings>
First of all, the codings element has a path
attribute which (as usual) specifies the directory in which codings
will be loaded from and saved to by default. Note that any
coding-file can override this default by specifying its own
path attribute (from release 1.3.0 on). Codings are divided into
agent-codings and interaction-codings in exactly the
way that signals are (we show only interaction
codings here). Each coding file will represent one entity on
disk per observation (and per agent in the case of agent codings).
The second observation is that codings are divided into
layers. Layers contain code elements which define the valid
elements in a layer. The syntax and semantics of these code
elements is exactly as described for object sets.
From 25/04/2006 Layers can point to each other using the
draws-children-from attribute and the name of another
layer. If your build is older, use the now-deprecated
points-to attribute.
For recursive layers like syntax, use the attribute
recursive="true" on the layer to mean that elements in the layer
can point to themselves.
The attribute recursive-draws-children-from=
means that elements in the layer can recurse but they must "bottom
out" by pointing to an element in the named layer. With builds pre
25/04/2006, use the now-deprecated layer-namerecursive-points-to attribute.
Layers are further described by their four types which are all described in detail in layer definition. REMOVE FROM THIS METADATA DESCRIPTION THE LAYER DEFINITIONS, WHICH ARE EARLIER IN THE DOCUMENT.
Layer types
- Time-aligned layer
elements are directly time-stamped to signal.
- Structural layer
elements can inherit times from any time-aligned layer they dominate. Times are not serialized with these elements by default. Structural layers can be prevented from inheriting times from their children. This is important as it is now permitted that parents can have temporally overlapping children so long as the times are not inherited. In order to make use fof this, use the attribute
inherits-time="false"on thestructural-layerelement. Allowing parents to inherit time when their children can overlap temporally may result in unexpected results from the search engine, particularly where precedence operators are used.- Featural layer
Elements can have no time stamps and cannot dominate any other elements - they can only use pointers.
- External reference layer
An external reference layer is one which contains a set of standard NITE elements each of has a standard
nite:pointerto an NXT object, and an external pointer to some part of a data structure not represented in NXT format. The idea is that when an application program encounters such an external element, it can start up an external program with some appropriate arguments, and highlight the appropriate element in its own data structure.
On disk, the above metadata fragment could describe the file
/home/jonathan/MockCorpus/o1.prosody.xml for observation
o1:
<nite:root nite:id="root1"> <accent nite:id="acc1" tobi="high"> <nite:child href="o1.words.xml#w_6"/> <nite:child href="o1.words.xml#w_7"/> </accent> <accent nite:id="acc1" tobi="low"> <nite:child href="o1.words.xml#w_19"/> <nite:child href="o1.words.xml#w_20"/> </accent> </nite:root>
A note on effective content models: the DTD content model equivalent of this layer definition
<structural-layer name="prosody-layer" draws-children-from="words-layer"> <code name="high"/> <code name="low"/> </structural-layer>
Would be (high|low)*. However, if a code has the
attribute text-content set to the value true (as for
the element word above) the content model for this element is
overridden and it can contain only text. This is the only way to allow
textual content in your corpus. Mixed content is not allowed
anywhere.
A metadata fragment looks like this:
<coding-file name="external" path="external"> <external-reference-layer element-name="prop" external-pointer-role="owl_pointer" content-type="text/owl" layer-type="featural" name="prop-layer" program="protege"> <pointer number="1" role="da" target="words-layer"/> <argument default="owl_file_1.owl" name="owl_file"/> <argument default="arg_value" name="further_arg"/> </external-reference-layer> </coding-file>
The corresponding data looks like this:
<propara> <nite:external_pointer role="owl_pointer" href="owlid42"/> <nite:child href="IS1008a.A.words.xml#id(IS1008a.A.words0)"/> </propara>
In the metadata fragment, you can choose to explicitly name the
program that is called using the program attribute, or you
can specify the content-type of the external file using a
content-type attribute (not shown in the metadata
fragment). Both are treated as String values and not interpreted
directly by NXT.
To help with housekeeping it's useful to know what programs have
been written for the corpus and how to call them. This also allows
NXT's top level interface list the programs and run them. Each
callable-program contains a list of required arguments. for example, a
program described thus:
<callable-programs>
<callable-program name="SwitchboardAnimacy" description="animacy checker">
<required-argument name="corpus" type="corpus"/>
<required-argument name="prefix" default=""/>
<required-argument name="observation" type="observation"/>
</callable-program>
</callable-programs>
Would be called java SwitchboardAnimacy -corpus
. The
metadata-path -prefix -observation obs-nametype attribute can take one of two values: corpus
meaning that the expected argument is the metadata filename and
observation meaning the argument is an observation
name. Arguments can also have default values. Note also that the
argument name or the default values can be empty strings.
Each observation in a corpus must have a unique name
which is used in filenames. This is declared in a list of observations
using the name attribute, for instance, like this:
<observations> <observation name="q4nc4"/> <observation name="q3nc8"/> </observations>
NXT currently includes the option of declaring two additional types of information for each observation: its categorization according to the observation variables that divide the corpus into subsets, and some very limited data management information about the state of coding for the observation. We expect in future to rethink our approach to data management which will probaby mean removing this facility from the metadata.
It has been pointed out that one might expect observations to have information mapping from agent (roles) to personal information about the individuals filling them in that observation (age, dialect, etc.). We don't propose a specific set of kinds of information one might wish to retain, because in our experience different projects have different needs (but see, for instance, the ISLE/IMDI metadata initiative). We also don't provide a specific way of storing it. This is partly because some of the information that projects retain falls under data protection and some of it doesn't, so there are issues about how it should be designed. At the moment, the best one can do is define a set of variables that together give the information one is looking for. We intend further improvements that will allow the corpus designer to specify a structure for the information and will allow private information to be kept in a separate file that is linked to from the metadata. Currently, the query language doesn't give access to the metadata about an observation, which means that it is only useful for deciding programmatically which observations to load as a filter on the entire corpus set, not for any finer-grained filtering. This also is something we hope to look at. Meanwhile, given these shortcomings, sometimes the best option is to store any detailed information in a separate file of one's own design and build variables that link agent roles to individuals in the separate file by idref.
Resource files are an adjunct to metadata files that provide
more flexible support for large cross-annotated corpora. A resource is
loosely a set of files that instantiate a particular
coding in the metadata file. For example, if both
fred and doris have taken
part in manual dialogue-act annotation, and an automatic process has
also been run to derive dialogue acts for all or part of the corpus,
all three would have their own resource in the resource file (see
example below).
Resource files should also specify dependencies between resources. This helps to ensure that coherent groups of annotations are loaded together. For example, an automatic dialogue act resource that was run over manual transcription must specify a different word-level dependency than a process run over ASR (automatic speech recognition) output.
Once a resource file is present for a corpus, loading multiple versions of the same coding becomes simpler, provided IDs are unique within the corpus. New annotation elements can even be added to the corpus while this kind of reliability data is loaded, because of the separation that resources afford us.
There is a simple API for creating resources programatically and it is hoped that a set of higher-level utilities will emerge to make this process easier.
The example resource file below illustrates most of the features provided by resource files.
<resources>
<resource-type coding="da-types">
<resource id="datypes" description="DA types" type="manual"
path="ontologies"/>
</resource-type>
<resource-type coding="dialog-act" default="true">
<virtual-resource id="da_gold">
<dependency observation="IS1008b" idref="da_doris"/>
<dependency observation=".*" idref="da_fred"/>
<dependency observation=".*" idref="da_doris"/>
</virtual-resource>
<resource id="da_doris" description="Dialogue acts manual version"
type="manual" annotator="Doris" path="dialogueActs/doris">
<dependency observation=".*" idref="AMIwordsref1"/>
<dependency observation=".*" idref="datypes"/>
</resource>
<resource id="da_fred" description="Dialogue acts manual version"
type="manual" annotator="Fred" path="/home/jonathan/fredDAs">
<dependency observation=".*" idref="AMIwordsref1"/>
<dependency observation=".*" idref="datypes"/>
</resource>
<resource id="da_auto1" description="Automatic DAs over manual words"
type="automatic" path="automanda1">
<dependency observation=".*" idref="AMIwordsref1"/>
<dependency observation=".*" idref="datypes"/>
</resource>
<resource id="da_auto1" description="Automatic DAs over ASR"
type="automatic" path="autoasrda1">
<dependency observation=".*" idref="AMIwordsASRa1"/>
<dependency observation=".*" idref="datypes"/>
</resource>
</resource-type>
<resource-type coding="words">
<resource id="AMIwordsref1" description="manual transcription"
type="manual" annotator="various" path="manual">
</resource>
<resource id="AMIwordsASRa1" description="ASR transcription"
type="automatic" annotator="various" path="../auto/ASR_AS1_feb07">
</resource>
</resource-type>
</resources>
The resource file consists of a set of resource-type
elements inside a containing resources element. Each
resource-type groups together a set of resources that instantiate the
same coding in the metadata file. Note that the word
coding is used here, but a resource can also
instantiate an ontology or similar corpus-level data file (see the
da-types resource group in the example above).
Paths in the resource file can be absolute, but if they are
relative, they are relative to the location of the resource file
(which itself may be relative to the metadata file). It is important
that each resource has a separate directory so that, for example, each
annnotator may code the same meeting in order to check inter-annotator
agreement. All files will be expected to conform to the NXT naming
conventions.
Each resource can have a list of dependencies. Virtual resources
are described below, but for a resource element,
dependencies will be to particular instantiations of the codings they
directly dominate and directly point to (there's no need to list
more remote descendents as dependencies).
Resources can be grouped into
virtual-resources. These groups do not specify a path but
instead exist solely to group a particular set of real resources. If a
gold standard coding exists for dialogue acts, as in the example above
(see the dialogue-act virtual resource called
da-gold), it can specify by means of
dependencies, how it is derived from the set of manual
dialogue-act annotations. So the da-gold resource derives its
gold-standard data for observation IS1008b from Doris; for all other
meetings that Fred has annotated, his annotation then takes
precedence; and for meetings that Fred has not annotated, we use
Doris's annoatation. Note that regular expressions are matched using
Java's java.util.regex. Note that virtual resources will
always have dependencies that point to resources in the same
resource-type group.
At most one resource inside each resource-type can be marked as
the default which means it will be the one loaded in the absence of
any explicit overriding instruction. See the da-gold
resource in the example above.
Finally, the notloadedwith attribute on a
resource element may specify exactly one other resource
which should never be loaded along with this one. This should not be
required particularly often, but may be useful if you have clashing
IDs and need to avoid co-loads, or if it would just be confusing for
users. If NXT is asked to load incompatible resources, it will print a
warning message.
Various rules are adhered to when loading files into NXT using a resource file:
two versions of the same coding are never co-loaded unless there's an explicit request. To request multiple loads, use the
forceResourceLoad(resource_id)orforceAnnotatorCoding(annotator, coding_id)methods ofNOMWriteCorpusWhenever a particular resource is loaded, its dependents automatically become the preferred resource for their respective codings. This is also true whenever a resource is the default in the resource file, or preferred / forced using an API call.
If elements in a high level coding are requested and some of its descendents are already loaded (or preferred), the resources that depend (however indirectly) on the already-loaded resources will be preferred.
Competing resources will be selected by applying these rules in order: choose manually forced resources from API calls; choose manually preferred resources, or those dependent on forced or preferred resources, or dependent on already-loaded resources; choose resources with their
defaultattribute in the resource file set totrue; choose virtual resources over ordinary resources.If there are multiple choices for which resource to load for a coding, and no single resource is derived using the algorithm above, the user will be asked to select a resource. Users can avoid these questions by selecting a coherent set of defaults in the resource file, or via API calls.
The only way to override this behaviour is to set the Java
property NXT_RESOURCES_ALWAYS_ASK to true. This forces
a user decision for every coding to be loaded (unless only one
resource instantiates the coding).
Resource files are validated when they are loaded. To avoid
confusion, it is advised but not enforced that paths to data locations
should be specified only in the resource file if it is present, rather
than allowing a mix of metadata and resource file paths. It is also
expected that if a resource file is present it should be complete in
terms of its coverage of metadata codings. Warnings will be also be
issued when coding attributes don't match valid elements
in the metadata file.
Resource files can affect data validation as they allow a
particular resource to refer to multiple resources that instantiate
the same coding. For example, an alignment element can refer to a
word in the reference transcription as well as a
word from the ASR version of the transcript. Before
resource files were introduced such an alignment would require the
ASR and reference word elements to have different types. The
disadvantage of using resources in this way is that such data
cannot be validated without extra effort.
In any framework, it is a good idea to test data sets to ensure that they are valid against the constraints of that framework's data representation. NXT's metadata file format and use of stand-off annotation to split a data set into a large number of files makes this somewhat trickier than for other XML data. For this reason, NXT comes with a method for validating data sets against their metadata files. NXT validation tests not just the validity of individual XML files from a data set, but also the validity of links between files. We explain how to validate NXT-format data and then describe a utility that helps with the process. In addition to the "off-line" validation described in the section, the methods for loading and editing data in the NITE Object Model perform some validation as they go along; see The NITE Object Model.
NXT's off-line validation relies on schema validation using a schema that unduly restricts the data format; the metadata format allows a number of options to be configured about the representation for a particular corpus, but the validation can only handle the default values. At present, the undue restrictions are as follows:
All stream elements (XML file document roots) must be named
nite:root.All ID, Start and End time attributes must use the NITE default names:
nite:id,nite:startandnite:end.All children and pointers must use XLink / XPointer style links, and ranges cannot be used. These are both handled automatically when
PrepareSchemaValidationis used.Annotations referring to elements of the same type from different resources cannot be validated without extra effort. This kind of annotation can be used for alignment of reference to automatic transcription etc.
In addition, even though the metadata file specifies which elements can occur at the first level under the stream element by constraining the tags that can occur in the file's top layer, the validation process currently fails to check this information, and will allow any elements at this level as long as those elements are valid and allowed somewhere in the data file.
- this reads information into JK's original - is the validation failure that any tag from the entire corpus can occur at the top level of any file?
- the schema for the metadata file is quite out-of-date. Can we fix?
If your data does not use XLink /XPointer style links but it
will load into NXT already, you can use NXT itself to change the link
style. The program
PrepareSchemaValidation.java will load the corpus and save
it in the correct link style, as well as carrying out a few more
of the required validation steps. It is in the samples directory
of the NXT distribution.
is PrepareSchemaValidation staying in samples? I think we should junk it completely and explain this one step here, and create a new schema validation utility that copies from the xalan sample Validate to create something that actually validates the data, without these restrictions and without the data having to load.
Before you begin, you need to be set up to perform schema validation using one of the many different methods available.
Schema validation comes as a command line utility from Apache in
the samples for Xalan. Although NXT redistributes Xalan, the
redistribution does not include the samples, which are in
xalansamples.jar.
To run schema validation, make sure xalansamples.jar and
xalan.jar are both on your classpath, and run
java Validate metadata-fileThis works for either schema or DTD validation.
XSV from http://www.ltg.ed.ac.uk/~ht/xsv-status.html is another common choice of validator. To run it, use
xsvfilenameschema
Alternatively, you can add the following attributes to the root element of the file you wish to validate
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="schema"
to name the schema in the document itself.
TEMP why is the instruction for xsv to add what is effectively the doctype as attributes to the root element - shouldn't this be by doctype instead?
There are a number of steps in validating an NXT corpus.
To validate the metadata file, run it through any ordinary
XML validation process, such as the schema validation
described in
FIX THIS LINK!
You can choose whether to validate the metadata file against
a DTD or a schema, whichever you find more convenient. The
correct DTD and schema can be found in the NXT distribution
in lib/dtd/meta-standoff.dtd and lib/schema/meta-standoff.xsd,
respectively.
the schema for metadata validation isn't in the NXT distribution that I can see - it's only available from the website as http://www.ltg.ed.ac.uk/NITE/metadata/schema.zip. That's not the right strategy.
What DOCTYPE should a metadata file have? We provide a catalog - do we want people using it?
TEMP we should remove the simple/stand-off corpus distinction, and only have stand-off, changing the documentation and the NXT source.
The stylesheet for generating a schema from an NXT metadata file
is in the NXT distribution in the lib directory. It
is called generate-schema.xsl.
You can use any stylesheet processor you wish to generate the
schema. Since xalan is redistributed with NXT, assuming you have
set $NXT to be the root directory of your NXT distribution,
one possible call is
java -cp "$NXT/lib/xalan.jar" org.apache.xalan.xslt.Process -in metadata
-xsl generate-schema.xsl -out extension.xsd
This creates a schema file called extension.xsd that
relies on two static schema files that are in the lib
directory of the NXT distribution: typelib.xsd and
xlink.xsd. Put these three files in the same directory.
The next step is to validate each of the individual XML files in the corpus.
To validate an NXT corpus you must check not just the individual
XML data files,
but also the child and pointer relationships represented by out-of-file links.
We do this by transforming each XML data file
so that instead of containing an XML element that
represents a link to an out-of-file child or pointer target, the file
contains the target element itself, and validating the resulting
files. The schema you have generated is set up so that it can validate
either the actual XML files in the corpus or the files that result from
this transformation. The stylesheet knit.xsl from the lib directory of the NXT distribution does the correct transformation; for
more information about knitting, see Knitting and Unknitting NXT Data Files.
Sometimes designers want the same pointer role from the same node type to be able to point to nodes drawn from not just one target layer, but from a disjunction of layers. There's no fix, so we don't mention it?
Because NXT does not itself commit the user to any particular data representation as long as it is expressed in terms of the NITE Object Model, it requires users to design their data sets by expressing formally what the annotations contain and how the annotation relate to each other. For complex data sets with many different kinds of annotations, there can be many different possible arrangements, and it can be difficult to choose among them, particularly for novice users. In this section, we comment on the design choices NXT presents.
Often in NXT data sets, there is a choice between whether to represent a relationship between two nodes as that of parent and child or using a pointer.
In general, prefer parent-child relationships except where that
violates the constraints of the NITE Object Model by introducing
cycles into the graph structure. If necessary, turn off time
percolation within a tree to have parent-child relationships make
sense. Trees are both faster to process and easier to access
within the query language; the hat operator (^)
calculates ancestorhood at any distance, but the pointer operator
(>) is for one level at a time.
The one exception is cases where using a pointer seems to fit
the semantics of the relationship more naturally and where
querying will not require tracing through arbitrary numbers of
nodes.
A tag set is a list of types for some annotation. For
instance, for a dialogue act annotation, two typical tags in the
set would be question and
statement. Dialogue acts would typically be
represented as a single layer of nodes that draw their children
from a transcription layer, but this still leaves the question of
how to represent their tag. There are three possibilities:
defining a different code in the layer for each tag and using this code, or "node type";
having one code but using an attribute defined using an enumerated attribute value list containing the tags;
or having one code that points into a separate ontology or other kind of corpus resource that contains nodes that themselves represent the tags.
The first option might seem the most natural, but it is
cumbersome in the query language because in searches over more than
one tag, each possible tag must be given in a disjunction for
matching the node type (e.g., ($d question |
statement)). A further advantage of the other two
representations is that NXT's query language provides regular
expression matching over attribute values; that is, if the tag set
includes two kinds of questions, yn-question and
wh-question and the tags are given as attribute
values on some node, then expressions such as ($d@tag ~
/.*question/) will match them both.
Of the other two representations, the simpler choice of
using an enumerated attribute value makes queries more succinct
(e.g., ($s dialogueact):($s@type=="question")
rather than ($s dialogueact)($t
da-type):($s>"type"$t):($t@name=="question")). However,
historically the configurable annotation tools could only be set
up using ontologies, forcing their use for data created using
these tools. The discourse segmentation and discourse entity tools
were changed in NXT version 1.4.0 to allow either method, and the
signal labeller is expected to follow suit shortly. For new
corpora, using an ontology retains two advantages. The first is
the ability to swap in different versions without having to change
the data itself, for instance, to rename the tags or change the
structure of the ontology. The second is for tag sets where the
designers wish to encode more information than can be packed
clearly into one string for use with regular expression matching
--- the nodes in an ontology can contain as many attributes as are
required to describe a tag or pointers to and from other data
structures, and can themselves form a tree structure instead of a
flat list. The latter is useful for testing tags by "supertype";
for instance, if all initiating dialogue act tags are grouped
together under one node in the ontology, whether or not an act is
an initiation can be tested e.g. by ($d dialogueact)($t
da-type)($s da-type):($d >"type" $t) && ($s ^ $t) &&
($s@name=="initiation") .
Check version of tools plus names of tools.
Ordinarily, orthography is represented using the textual content of a node. Alternatively, orthography can be represented in a user-defined string attribute.
There are several advantages to representing orthography as textual content. The first is for processing outside NXT --- since textual content is a common representation, there are a number of XML tools that expect to find orthography there already. The second is that the configurable tools also expect this, and so they will work for data represented this way without the need to modify how they render transcription by writing delegate methods specifically for the corpus. However, using the textual content is not always practicable. This is because in the NITE Object Model, nodes can have either textual content or a set of children, but not both. Although different, rival orthographies for the same signal can be accommodated easily using different, rival transcription layers, complex orthographic encodings which require orthography at different levels in the same tree cannot. As an example, consider cases where a word was said in a reduced form (e.g., "gonna"), but it is felt necessary to break this down further into its component words ("going" and "to"). If this is to be represented as one element decomposed into two, the top one cannot have textual content, and therefore orthography must be represented using a string attribute.
The reason why NITE Object Model nodes cannot have both textual content and children is to make it clear how to traverse trees within it. If a node had both, we would not know whether the textual content should come before the children, after them, or somewhere in the middle. The reason it was included was because it was considered useful to treat the orthography as special within the data representation. One might, for instance, consider the textual content of a node to be a concatenation of the textual content of its children in order using some appropriate separator. We are currently discussing whether the NITE Object Model ought to perform this operation in future versions, or whether we ought to deprecate the use of textual content altogether in favour of string attributes that concatenate except where overridden at a higher level in the tree.
Check accuracy of text content/child statement. Check percolation with JK.
Ordinarily, we would recommend the use of namespaces throughout a
data set, particularly where a corpus is expected to attract many
different annotations from different contributors. However, NXT's
query language processor has historically contained a bug which
means that it is unable to parse types and attribute names that
contain namespaces. This is not a problem for default use of the
nite namespace because the query language exposes the
namespaced attributes using functions (e.g., ID($x)
for $x@nite:id, but it is for user-defined uses of
namespacing. We expect this problem to be resolved at some point
in the future (after version 1.3.7) but not as a high priority.
Put in Sourceforge bug number?
The set of intersecting trees in a set of annotations constrains how the data will be stored, since each tree must be stored in a different file (or set of files, in the case of agent annotations). However, it does not fully specify the division into files, since NXT has both in-file and out-of-file representations for parent-child relationships. Data set designers can choose to store an entire tree in one file (or set of files) or to split the tree into several files, specifying which layers go in each.
Dividing a tree into several files can have several benefits. The first is that since NXT lazy loads one file at a time as it needs it, it can mean less data gets loaded over all, making the processing quicker and less memory-intensive. The second is that each file is simpler, making it easier to process as plain old XML, especially the base layers, since these have no out-of-file child links. The third is that during corpus creation, assuming some basic ground rules about building layers up from the bottom, each file can be edited independently. However, dividing a tree into several files also has some drawbacks --- the data takes more space on disk it parent-child relationships are represented as out-of-file links rather than using the structure of the XML file, and there is a processing overhead involved in the operation of loading each file.
A good general rule of thumb is to consider whether use of one layer means that the other layer will also be needed. Unless most users will always want the two layers together, both inside and outside NXT, then store them in different files.
Sometimes, the layering model imposed by NXT metadata is more rigid than a corpus designer would like. It can be useful to allow some nodes in a layer to draw children not from the declared next layer, but from the layer directly below it, skipping a layer completely. This can be the case when the middle layer contains some phenomenon that covers only some of the lowest level nodes. For instance, suppose one intends a corpus with dialogue act annotation and some kind of referring expression markup, both over the top of words. Referring expressions are within acts, so it would be possible to have them between acts and words in one tree, if the layer structure allowed acts to mix words and referring expressions as children.
Some NXT corpora have simply violated the layer model in this way, and at present, for the most part it still works; however, because NXT by default uses "lazy loading" to avoid loading data files when it knows they are not needed, users of these corpora must turn lazy loading off - a major cost for memory and processing time that is untenable for larger data sets - or else consider for each data use whether lazy loading is safe in that instance. In addition, relying on NXT's current behaviour in this regard may be risky as the software develops. There are several other options.
The first is to separate out the middle and top layers into separate trees, making them both draw children from the bottom layer, but independently. (This has the side effect of serializing them into different files.) Then nodes in the top layer are no longer parents of nodes in the middle layer, but they can be related to each other via the nodes from the bottom layer that they both contain.
The second is to wrap all of the unannotated node spans from the bottom layer with a new node type in the middle layer, and have the top layer draw children from the bottom layer indirectly via these new nodes. The additional nodes would take some storage space and memory. The one thing that might trip corpus users up about this arrangement is if they use distance-limited ancestorhood in queries, since they would be likely to forget the nodes are there.
The third is to declare the top and middle layers together as one recursive layer, which means as a side effect that they must be serialized to the same file. This method behaves entirely as desired, but prevents NXT from validating the data correctly, since NXT allows any node type from a recursive layer to contain any other node type from the layer as a child.
This section explains how to use the Build utility of NXT
to produce packaged-up versions of your corpus in a way that other
users can unpack and use. You can specify which annotations and
observations are included, and an appropriate metadata file will be
produced to go along with the data you select.
To specify a data build for an NXT corpus you need to follow these steps:
Write a build specification file conforming to the simple DTD file in your distribution (see
lib/dtd/build.dtd)With NXT and its various lib jar files on your
CLASSPATH, runjava net.sourceforge.nite.util.Build
yourfileThis creates an
antfile to actually do the build. You will also be told what command to issue...Run
ant -fto produce a data file (you'll be told what the data file is called).your_antfile
First, here's a valid build specification. The resulting ant
file extracts a set of words and abstractive summaries from all
observations matching the regular expression Bed00*. We take the
standard words from the corpus, but for the abstractive summary, we
decide we want to use the files from the annotator
sashby.
<build metadata="Data/ICSI/NXT-format/Main/ICSI-metadata.xml"
description="ICSI extract" name="jonICSI"
type="gold" corpus_resources="off" ontologies="on" object_sets="off">
<extras dir="/home/jonathan/configuration" includes="*.html" dir="config"/>
<coding-file name="words"/>
<coding-file name="abssumm" annotator="sashby"/>
<observation name="Bed00*"/>
</build>
There are two types of build: gold and
multi-coder. The first of these is for builds where we
want only one set of XML files for each coding and for that set to be
treated as the gold-standard. Note that in the
example above we actually chose a specific annotator's abstractive
summary: in the resultant build, that annotator's abstractive
summaries will replace any existing 'gold-standard' abstractive
summaries. Multi-coder builds result in corpora which may have
gold-standard codings, but can also have all the
different annotators' data included. There's an example below.
Output of any of the corpus-wide information can be toggled on
or off, using attributes of the same name:
corpus_resources; ontologies;
object_sets. They are all output by default. Arbitrary
extras can also be included in the build. These
are essentially specs that are passed straight through to ant.
<build metadata="Data/ICSI/NXT-format/Main/ICSI-metadata.xml" description="ICSI multi-coder extract" name="jonICSImulti" type="multi_coder"> <coding-file name="words"/> <coding-file name="abssumm"/> <coding-file name="extsumm" resource="autoextract1"/> <observation name="Bmr*"/> </build>
This requests the words and abstractive summary codings as before, but
for a different set of observations. This time we'll end up with the
gold-standard words (since that's all there is in our corpus), but the
entire tree of abstractive summaries including any 'gold-standard'
files plus subdirectories of all the annotators' abstractive
summaries. Note that if an annotator is named in multi-coder mode,
only that annotator's data is included but it is not raised to the
gold-standard location. Finally (from NXT release 1.4.2; CVS date
14/09/2007), note the extra coding-file extsumm which has
an associated resource attribute. This attribute will
have an efect on the build if there's a resource file referred to in
the metadata file and it contains a resource for extractive summaries
called autoextract1. In that case, the resource file will
be included in the build, and the selected resource is the one used
for extractive summaries. You can have multiple instances of the same
coding-file to include multiple competing resources.
One extra element allowed is a default-annotator element
before any of the coding-file elements: the name
attribute of will be the name of the annotator that is used by default
(where not overriden by an annotator element on a
coding-file element).
Note
In any circumstance where a specific annotator's data has been requested, but there is none present, the 'gold-standard' data (if present) will be used instead.