
Practical Examples
This chapter describes some examples of using the geoparser with text from different domains, such as modern text, historical documents and classical works in English translation. Using the command line parameters you can switch different lexicons and gazetteers on or off, to suit different kinds of text. Each of the examples below looks at different aspects of the output produced.
The examples here are for the domains we have tested, and the relevant
files are included in the distribution (in the in directory) so
you can run the examples as described below. These are real texts we
have worked with, not prepared examples, and the output will contain
errors - of precision or recall over the entities, or through
mis-idendification of locations. The publications in Appendix 2: LTG Publications about the Geoparser
discuss the performance you can expect in various domains.
If your domain fits one of these categories you should be able to use
the geoparser without adaptation, by simply specifying the -t type
and -g gazetteer parameters appropriately. See -t and -g
parameters for the available options.
For a discussion of the issues involved in customising the geoparser for a new domain, see Adapting the Edinburgh Geoparser for Historical Geo-referencing in the Appendix 2: LTG Publications about the Geoparser chapter.
Modern text
Plain text: “burtons.txt”
We start with a simple example using the file “burtons.txt”, without creating any visualisation files, and writing to stdout. Here the command is being run from the geoparser root directory, but it could be run from anywhere, with appropriately specified paths:
cat in/burtons.txt | scripts/run -t plain -g unlock
The following command, using input redirection instead of a pipe, is of course completely equivalent:
scripts/run -t plain -g unlock < in/burtons.txt
This run uses Edina’s Unlock gazetteer which is mainly UK oriented. The input file starts like this:
How the home of Mini Rolls and Smash was gobbled up
Food factory workers facing the the sack will march on Saturday for an
economy that values more than just money
Among the thousands of people who join the big anti-cuts march this
Saturday will be a coach load from Wirral. ...
The output starts like this:
<?xml version="1.0" encoding="UTF-8"?>
<document version="3">
<meta>
<attr name="docdate" id="docdate" year="2014" month="07" date="02"
sdate="2014-07-02" day-number="735415" day="Wednesday" wdaynum="3">20140702
</attr>
<attr name="tokeniser_version" date="20090526"/>
</meta>
<text>
<p>
<s id="s1">
<w pws="yes" id="w13" p="WRB" group="B-ADVP">How</w>
<w pws="yes" id="w17" p="DT" group="B-NP">the</w>
<w l="home" pws="yes" id="w21" p="NN" headn="yes" group="I-NP">home</w>
<w pws="yes" id="w26" p="IN" group="B-PP">of</w>
<w common="true" l="minus" pws="yes" id="w29" p="NNP" event="true"
headn="yes" group="B-NP">Mini</w>
<w common="true" vstem="roll" l="roll" pws="yes" id="w34" p="NNP"
event="true" headn="yes" group="I-NP">Rolls</w>
<w pws="yes" id="w40" p="CC" headn="yes" group="I-NP">and</w>
<w common="true" l="smash" pws="yes" id="w44" p="NNP" event="true"
headn="yes" group="I-NP">Smash</w>
<w l="be" pws="yes" id="w50" p="VBD" group="B-VP">was</w>
<w l="gobble" pws="yes" id="w54" p="VBN" headv="yes" group="I-VP">gobbled</w>
<w pws="yes" id="w62" p="RP" group="I-VP">up</w>
</s>
</p>
...
The complete file is here
(html documentation only).
The output is xml with paragraphs and sentences marked and individual
tokens in <w> elements, with various linguistic attributes
added. The unique “id” attribute is based on character position in the
input text. Some meta data has been added, including a “docdate” which
defaults to the current date as no -d docdate parameter was
specified. Placename mentions found in the text will have a “locname”
attribute on the <w> element, but this is part of the intermediate
processing, and the final Named Entity markup is specified using
standoff xml as described below.
The <text> element is followed by a <standoff> section. The
following sample shows the structure:
<standoff>
<ents source="ner-rb">
<ent date="05" month="07" year="2014" sdate="2014-07-05" day-number="735418
id="rb1" type="date" day="Saturday" wdaynum="6">
<parts>
<part ew="w125" sw="w125">Saturday</part>
</parts>
</ent>
...
</ents>
<ents source="events">
<ent tense="past" voice="pass" asp="simple" modal="no" id="ev1"
subtype="gobble" type="event">
<parts>
<part ew="w54" sw="w54">gobbled</part>
</parts>
</ent>
...
</ents>
<relations source="temprel">
<relation id="rbr1" type="beforeorincl" text="was gobbled up">
<argument arg1="true" ref="ev1"/>
<argument arg2="true" ref="docdate"/>
</relation>
...
</relations>
</standoff>
There are two sets of <ents> elements because the pipeline uses
two separate steps. The first is a rule-based process (“ner-rb”) to
identify and classify the entity mentions - the above example shows a
date entity. The entity categories detected are: date,
location, person, and organisation. The entities are tied
back to their positions in the text by the <part> element, which
has “sw” (start word) and “ew” (end word) attributes whose values
match the “id”s on the <w> s in the text.
The second set of <ents> are mainly verbs and verb phrases, tagged as
a basis for detecting events mentioned in the text. The
<relations> section relates pairs of <ent> s, identified by a
“ref” attribute that points to event <ent> s (such as “ev1”) or
rule-based ones (eg “rb1”) or to the docdate as in this example.
From a purely geoparsing point of view, only the rule-based “location” entities may be required, which look like this:
<ents source="ner-rb">
<ent id="rb3" type="location" lat="53.37616" long="-3.10501"
gazref="geonames:7733088" in-country="GB" feat-type="ppl">
<parts>
<part ew="w288" sw="w288">Wirral</part>
</parts>
</ent>
<ent>
These can easily be extracted if desired. (For example one could extract these with lxgrep or remove other unwanted nodes with lxreplace, both of which are included in the LT-XML2 toolkit). Tools to create the rest of the markup have been added to the pipeline at various times for different projects and the full output is included because why wouldn’t we?
News text with known date: “172172”
With news text the date of the story is often known, and can be
specified to the geoparser to help with event detection. The next
example also specifies the -o outdir prefix option so that a full set
of visualisation files will be produced in addition to the main output
described above (which will be in a file named
“outdir/prefix.out.xml”):
cat in/172172.txt |
scripts/run -t plain -g geonames -d 2010-08-13 -o out 172172
In this case we have directed output to the pipeline’s out
directory but it can be sent anywhere using a relative or absolute
path. The online Geonames gazetteer has been chosen, as the text
doesn’t relate to the UK. It begins:
Nadal and Murray set up semi showdown
(CNN) -- Rafael Nadal and Andy Murray are both through to the
semifinals of the Rogers Cup in Toronto, where they will face each
other for a place in Sunday's final.
Murray played some superb tennis in crushing the in-form David
Nalbandian but Nadal had to recover from dropping the opening set to
get past Germany's Philipp Kohlschreiber.
Nalbandian won the ATP title in Washington last weekend and came
into Friday's encounter on an 11-match unbeaten streak. ...
Specifying the -o option means that, instead of just the tagged
text file, we get a collection of output files:
- 172172.display.html
- 172172.events.xml
- 172172.gaz.xml
- 172172.gazlist.html
- 172172.gazmap.html
- 172172.geotagged.html
- 172172.nertagged.xml
- 172172.out.xml
- 172172.timeline.html
The output files are described in the Quick Start Guide, Visualisation output: -o. We looked at the format of the “172172.out.xml” file above. The other main file is “172172.display.html”, which looks as shown in Figure Geoparser display file for news text input. The map window uses Google Maps to display the placename locations, with green markers for the top-ranked candidate for each place and red markers for the other candidates. The bottom left panel shows the input text, with placenames highlighted, and the bottom right panel lists the placenames with all the candidate locations found for each. The first in the list is the chosen one, in green. You can see from the lenghth of the horizontal scroll bar that there are typically a great many other candidates - this is especially true when using Geonames, as common placenames like the ones in this file are repeated many times all over the world. The display is centred on the first placename mention, “Toronto”, and can be re-centred by selecting other lat/long positions from the placename list.
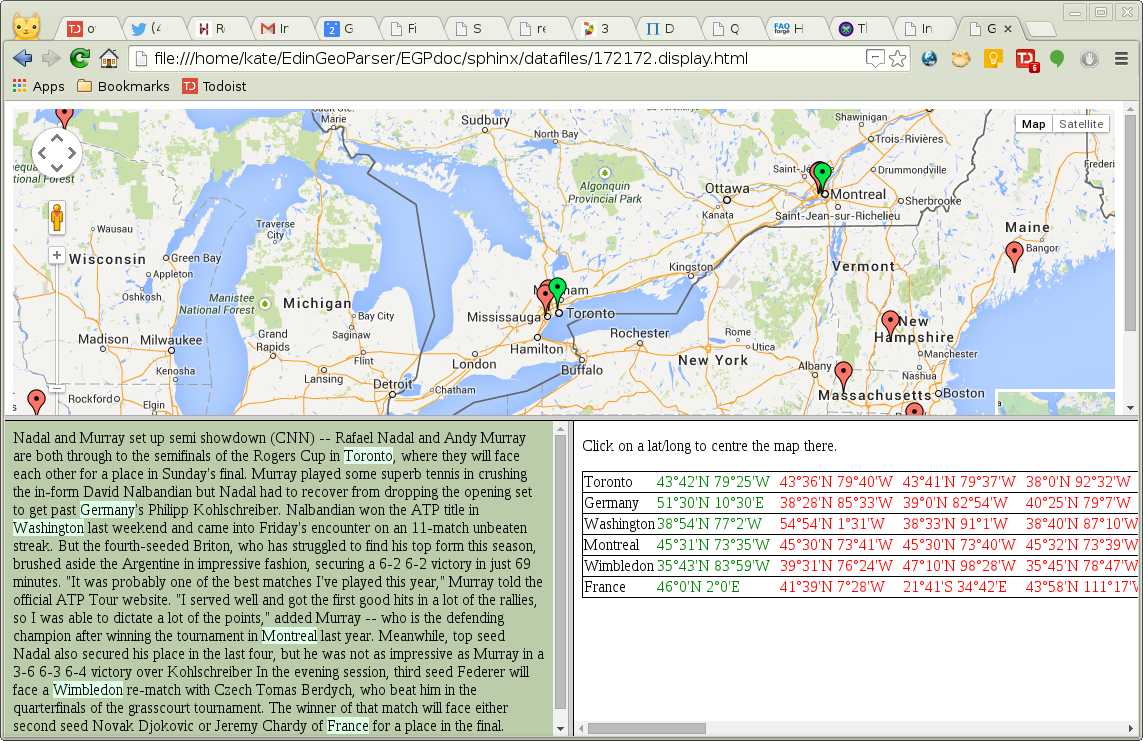
Geoparser display file for news text input
This was quite a short file to try to detect events in, but those
found are listed in “172172.events.xml” (available here in the html documentation), which is
used to produce the Timeline display shown in Figure
Timeline file. (Note that the Chrome browser will only display
the timeline correctly if served from a web server. Firefox is less
fussy and will display the page as illustrated from a file://...
URI.)
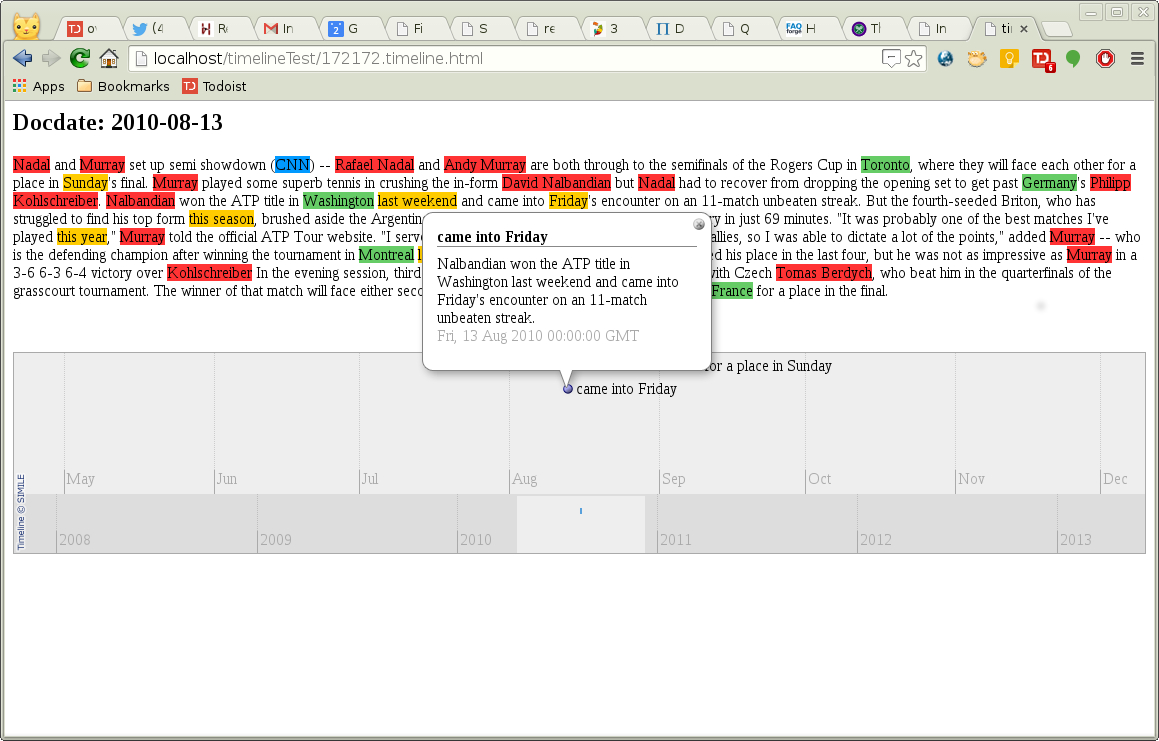
Timeline file
This display shows other entity categories besides the locations, which are in green. Personal names are in red, organisations in blue and time expressions in yellow. The pipeline detected 5 events in this input but was only able to assign specific dates to two of them, which are the two plotted on the timeline. The other events included references to “this season” and “this year”, which couldn’t be placed on the timeline. In the screen shot, an “info” box has been brought up, by clicking on one of the events. It shows the text of the event and its timestamp.
Historical documents (relating to England)
We now take a more complex example, using some historical text. The input file is “cheshirepleas.txt”, which starts thus:
On Saturday (fn. 2) next after the feast of St. Edward the King in
the 33rd year of the reign of King Edward [1305] Robert le Grouynour
did his homage and fealty for all the tenements of Lostoke, and
acknowledged that he held the manor of Lostoke entirely from the manor
of Weverham for homage and service and fealty [fo. 38d (275 d)] and
suit at the court of Weverham every fortnight, and 17s. yearly to the
manor of Weverham at the four terms, and two customary pigs, and four
foot-men in time of war at Chester bridge over the Dee, when Weverham
finds eight foot-men, and three when the manor of Weverham finds six,
or two when Weverham finds four men, with the ward and relief of
Lostok for all service. ...
The appropriate gazetteer for this text is DEEP, a specialist
gazetteer of historical placenames in England (see footnote [1] in the Quick Start Guide for details). If we know
that the text is about Cheshire we can restrict the gazetteer to that
county. The text deals with dates in the 14th century - in fact over
several different years, despite the rather specific sound of “On
Saturday next”, so whilst a docdate parameter may not be
appropriate, we can limit the DEEP candidates to ones attested for the
medieval period, using a date range (say for the 12th to 14th
centuries). The run command we will use is:
cat in/cheshirepleas.txt |
scripts/run -t plain -g deep -c Cheshire -r 1100 1400 -o out chespleas
In this case we have specified that a full set of output files should
be produced, in the usual out directory and prefixed with the
string “chespleas”. Figure Display file for Cheshire input and DEEP gazetteer shows the display
file created. The blue underlined placenames in the text window are
embedded links back to the source gazetteer material for the toponym at
placenames.org.uk [http://placenames.org.uk].
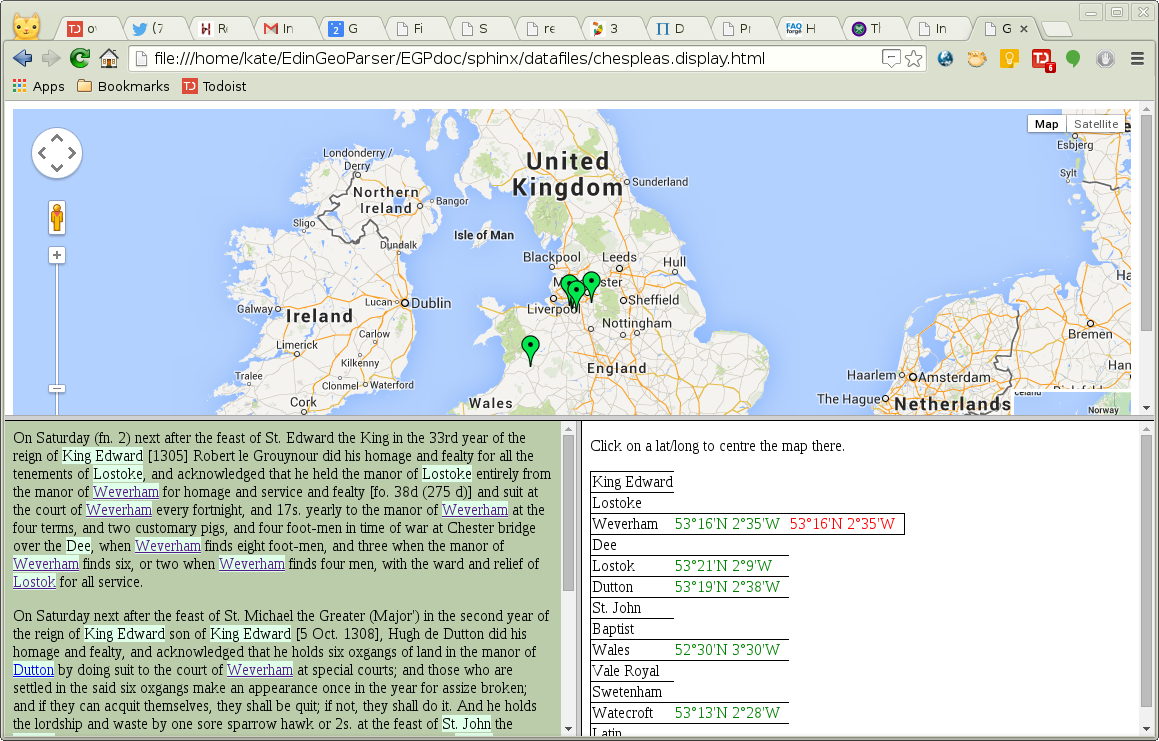
Display file for Cheshire input and DEEP gazetteer
As expected, the chosen locations are clustered together in Cheshire, the single outlier being a reference to “Wales”.
Classical texts
As part of the GAP [http://googleancientplaces.wordpress.com/] (Google Ancient Places) project, the geoparser was adapted to deal with classical texts in English translation. This requires different lexicons of places and personal names and uses the Pleiades [http://pleiades.stoa.org/] gazetteer of ancient places. (See the Pleiades+ section for details of Pleiades and Pleiades+.)
The geoparser output was post-processed by the GAP project to creat
the GapVis display (versions 1 [http://nrabinowitz.github.io/gapvis/]
and 2 [http://enridaga.github.io/gapvis/gap2/] are currently
available). This only requires one location per toponym mention so
only the top-ranked candidate was passed on. If you only require the
“best” location (the green markers in the displays above) then specify
the -top option:
cat in/herodotusBk1.txt |
scripts/run -t plain -g plplus -o out hbk1plplus -top
The -top option can be used for any input and will result in an
extra set of display files being produced, in which the unsuccessful
candidate locations have been removed. The display page in this
example will be file “out/hbk1plplus.display-top.html”, which is
illustrated in Figure Herodotus display file. The text is the opening
of Book 1 of the Histories by Herodotus.
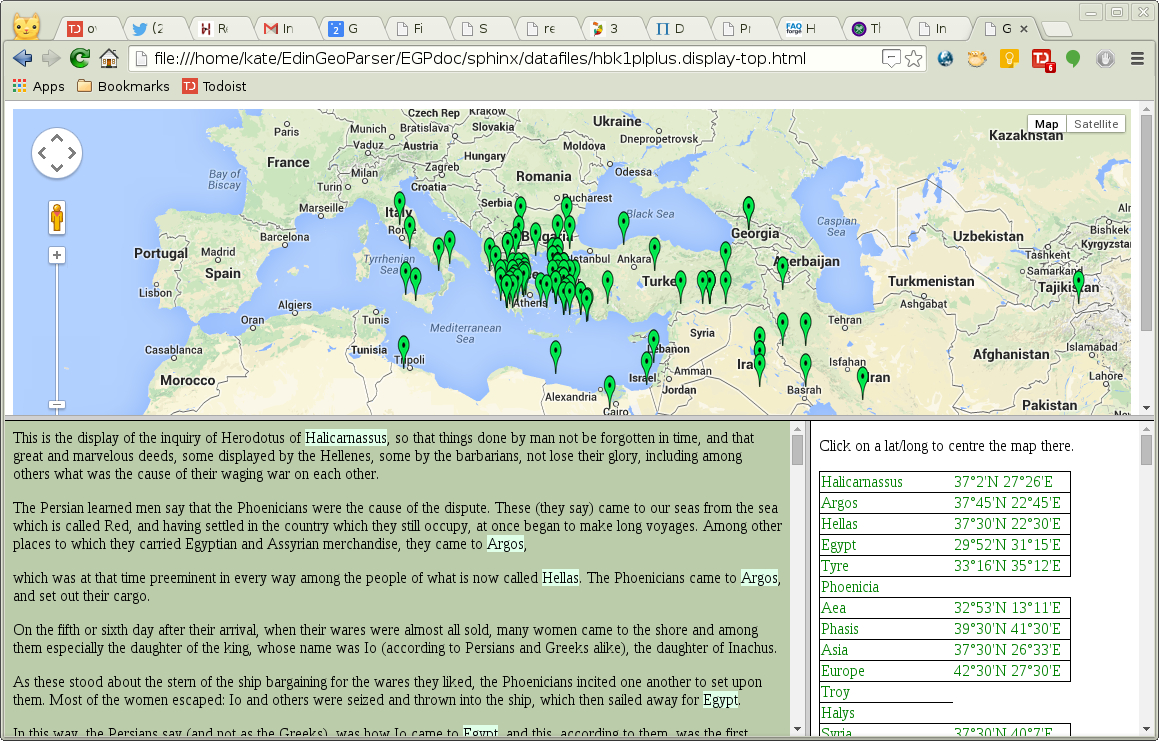
Herodotus display file
In principle it might be possible to process input in the original Latin or Greek (or indeed in any language), if suitable linguistic components could be substituted in the geotagging stage of the pipeline. This is a project for another day. The Hestia 2 [http://hestia.open.ac.uk/hestia-phase-2/] project has taken steps along the way towards allowing students to work with the Greek version of the Histories.
Using pre-formatted input
The examples above all use plain text input files. If your input files
already contain markup, such as html or xml, you may wish to alter the
pre-processing steps of the pipeline to cater for it. Alternatively,
it may be simpler to strip the markup and treat your input as plain
text. The type parameter accepts two specific formats, gb
(Google Books html files) and ltgxml (a simple xml style used by LTG, that
has paragraphs pre-marked; see sample file in/172172.xml for the format).
Google Books format
Another spin-off from the GAP project was the need to process Google
Books input. GAP was a Google-funded project using bulk quantities of
Google Books material, specifically classical texts. The original
scanning and OCR work was done on a very large scale by Google and the
quality can be variable to say the least. The data was made available
as html files and we had the choice of either stripping all the
markup - which would have thrown away valuable information - or
attempting to ingest the raw files. The prepare stage at the start
of the pipeline was amended to do just enough pre-processing of the
html to ensure that the many non-printable characters contained in the
OCR-ed input don’t break the xml tools. Because the files vary so much
from book to book it was not possible to do more detailed
tailoring. If this was required, the prepare-gb script might be a
starting point.
The following example uses another edition of the Herodotus text, taking a single page from a Google Books edition as input:
cat in/gb_pg234.html | scripts/run -t gb -g plplus -top -o out gb_pg234
The output files are similar to those already shown and are available
in the out directory.
The Open Library [https://openlibrary.org/] provides an alternative source of scanned and OCR-ed texts, and experiments were also done with material from this source. The text displays many of the same OCR errors but is available as plain text (as well as other formats less useful for processing) rather than html.
XML input
The “172172.txt” input used above was actually orginally generated as xml, in the “ltgxml” format - the plain text version has the markup stripped out. In the ltgxml format the docdate can be included if known:
<?xml version="1.0" encoding="UTF-8"?>
<document version="3">
<meta>
<attr name="docdate" id="docdate" year="2010" month="08" date="13"
sdate="2010-08-13" day-number="733996" day="Friday" wdaynum="5"/>
</meta>
<text>
<p>Nadal and Murray set up semi showdown</p>
<p>(CNN) -- Rafael Nadal and Andy Murray are both through to the semifinals
of the Rogers Cup in Toronto, where they will face each other for a
place in Sunday's final.</p>
<p>Murray played some superb tennis in crushing the in-form David Nalbandian
but Nadal had to recover from dropping the opening set to get past
Germany's Philipp Kohlschreiber.</p>
<p>Nalbandian won the ATP title in Washington last weekend and came into
Friday's encounter on an 11-match unbeaten streak.</p>
...
We would get identical output to that obtained above (give or take white space) with this command:
cat in/172172.xml | scripts/run -t ltgxml -g geonames -o out 172172
The -t type is changed to reflect the input and the -d docdate is
no longer required.
Apart from the docdate specification, the other substantive difference with using xml input is that paragraph markers can be passed to the pipeline if you already have them.