Related Work
-
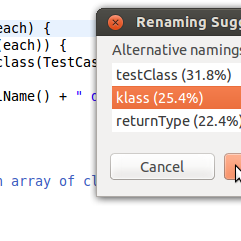
Learning Natural Coding Conventions
Allamanis, Barr, Bird, Sutton.
ACM Distinguished Paper Award
In our previous work we use language models to suggest renamings of variables and formatting changes to retain the stylistic consistency of a codebase. [link]
-

REPENT: Analyzing the Nature of Identifier Renamings
Arnaoudova, Eshkevari, Di Penta, Oliveto, Antoniol, Gueheneuc
An analysis of why and when renamings happen. [link]
-
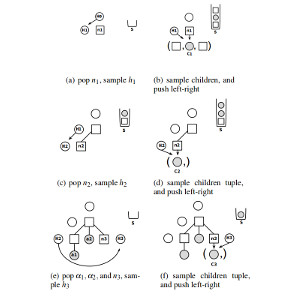
Structured Generative Models of Natural Source Code
Maddison and Tarlow
The first log-bilinear language model of source code. This paper shows another way of applying log-bilinear models to source code ASTs. [link]
-
On the naturalness of software
Hindle, Barr, Su, Gabel, Devanbu
The seminal paper of the area, that showed that source code is predictable and amenable to statistical and machine-learning methods. [link]




